📝 Paper Summary
Inference Acceleration
KV Cache Optimization
SFI accelerates LLM decoding by updating the active memory cache only at semantic boundaries (Slow steps) and reusing it for most tokens (Fast steps), exploiting the stability of attention patterns within sentences.
Core Problem
Long-context autoregressive decoding is computationally expensive because the model repeatedly performs attention over the entire growing history at every single step, even though attention patterns rarely change token-by-token.
Why it matters:
- Inference latency scales poorly with context length, making long-context applications (like analyzing books or long agent histories) prohibitively slow
- Existing sparse methods often permanently evict information or require model retraining, while retrieval-based methods incur heavy overhead for every step
Concrete Example:
In a long chain-of-thought reasoning task, generating a simple 20-token sentence explaining a step currently requires the model to re-scan thousands of past tokens 20 times. SFI observes the relevant context is stable for that sentence, scanning the history once and reusing the result 19 times.
Key Novelty
Slow-Fast Inference (SFI)
- Decouples decoding into frequent 'Fast steps' (using a small, fixed-size sparse cache) and rare 'Slow steps' (performing dense attention to refresh the cache)
- Uses a 'Selector' module that fuses dense attention evidence with structural priors (via a closed-form KL divergence solution) to smartly update the sparse memory
- Triggers expensive cache refreshes only at semantic boundaries (e.g., punctuation) where attention shifts are naturally likely to occur
Architecture
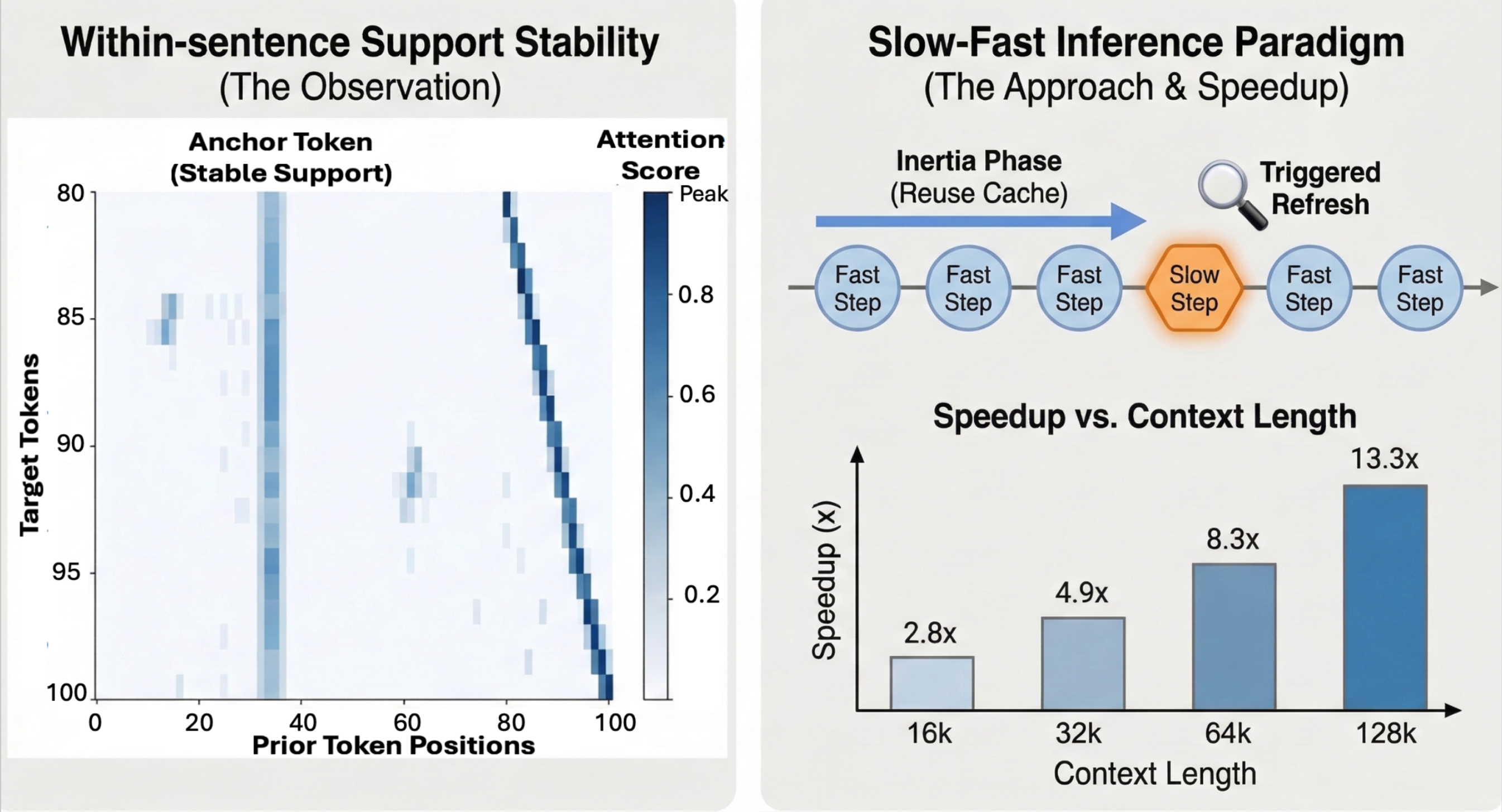
The Slow-Fast Inference (SFI) workflow, illustrating the switching mechanism between Fast and Slow steps
Evaluation Highlights
- Achieves 1.6x to 14.4x higher decoding throughput compared to full-KV baselines across evaluated context lengths
- Maintains generation quality near-parity with full-KV baselines on long-context understanding and long-Chain-of-Thought tasks
Breakthrough Assessment
8/10
Offers a significant speedup (up to 14x) for the critical bottleneck of long-context inference without requiring any training or model modification. The semantic-boundary trigger is a clever, intuitive insight.