📝 Paper Summary
Medical Vision-Language Models (Med-VLM)
3D Brain MRI Analysis
Longitudinal Disease Progression Modeling
LoV3D trains a 3D vision-language model to produce verifiable, structured clinical reports for longitudinal brain MRI by using a clinically-weighted Verifier to drive Direct Preference Optimization without human annotations.
Core Problem
Current tools fragment diagnosis: classifiers produce labels without reasoning, volumetric tools (like FreeSurfer) give numbers without interpretation, and VLMs generate fluent but hallucinated text that is hard to verify.
Why it matters:
- Clinical reports require layered reasoning (anatomical observations, longitudinal comparison, clinical context), not just a final label, to be trusted by neuroradiologists.
- Existing VLMs can describe atrophy in healthy patients because they lack anatomical grounding, and no algorithm can detect these hallucinations from free text alone.
- Deep learning classifiers discard anatomical specificity, while volumetric pipelines lack the reasoning capabilities to synthesize findings into a diagnosis.
Concrete Example:
A generalist VLM might describe hippocampal atrophy in a patient whose hippocampus is actually normal. Because the output is free text, no algorithm can flag this error automatically. In contrast, LoV3D outputs structured JSON where the label 'normal' is cross-checked against the reasoning text and longitudinal history.
Key Novelty
Closed-loop verifiable training via structured outputs and automated DPO
- Design the model output as structured JSON where fields (anatomy, diagnosis, reasoning) have explicit logical constraints checkable by code, rather than just free text.
- Use a 'Clinically-Weighted Verifier' that scores generated outputs against ground-truth volumetric data (derived from FreeSurfer but never shown to the model input) to create preference pairs.
- Train the reasoning process using Direct Preference Optimization (DPO) based on these automated scores, eliminating the need for human preference labeling.
Architecture
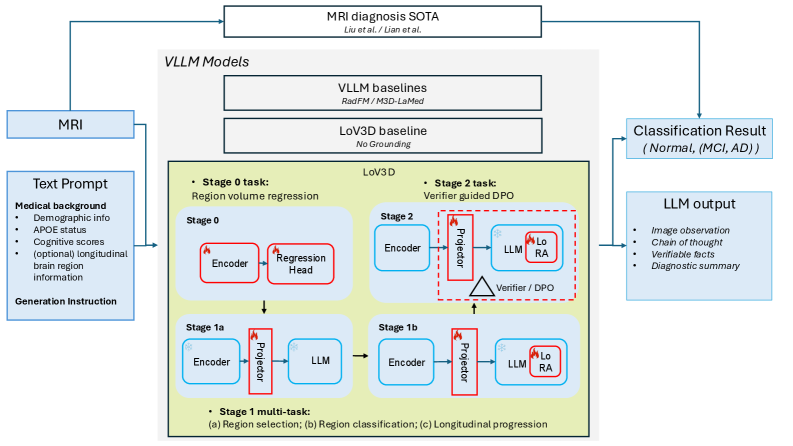
End-to-end training pipeline and inference workflow, showing the progression from Stage 0 to Stage 2.
Evaluation Highlights
- 93.7% three-class diagnostic accuracy (CN/MCI/Dementia) on ADNI test set, with zero non-adjacent errors (e.g., no CN identified as Dementia).
- 97.2% two-class accuracy (CN vs. Dementia), outperforming SOTA binary classifiers by +4% on the same split.
- 82.6% region-level anatomical classification accuracy, improving +33.1% over generalist VLM baselines (RadFM, M3D-LaMed).
Breakthrough Assessment
9/10
Strong contribution by solving the VLM hallucination problem via structured verification and automated DPO. Achieves SOTA on ADNI and zero-shot transfer to external datasets without human annotation.