📊 Experiments & Results
Evaluation Setup
Single-attempt (pass@1) evaluation on 900 puzzle instances (6 families x 3 difficulties x 50 instances)
Benchmarks:
- TopoBench (Topological Grid Puzzles) [New]
Metrics:
- Accuracy (pass@1)
- Statistical methodology: 95% Wilson score confidence intervals reported for intervention experiments
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Frontier models struggle significantly as difficulty increases, with hard puzzles remaining largely unsolved. | ||||
| TopoBench (Hard Tier) | Accuracy | 0.10 | 0.24 | +0.14 |
| Causal interventions demonstrate that 'Premature Commitment' and 'Constraint Forgetting' are the primary drivers of failure. | ||||
| Bridges (Intervention) | Accuracy | 0.768 | 0.560 | -0.208 |
| Bridges (Intervention) | Accuracy | 0.768 | 0.662 | -0.106 |
| Tool augmentation experiments show that accessing structured state information significantly boosts performance. | ||||
| Bridges (Hard) | Accuracy | 0.40 | 0.50 | +0.10 |
Experiment Figures
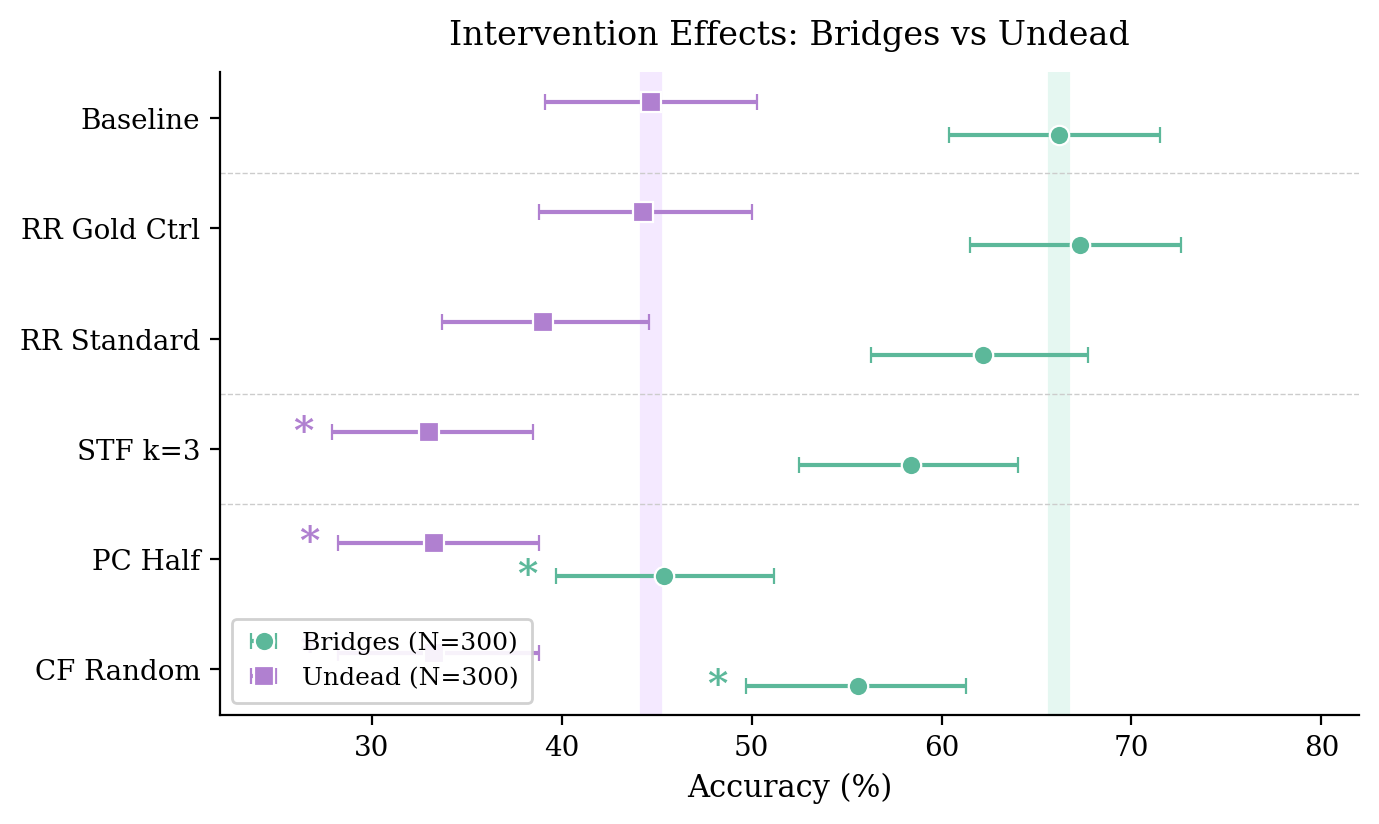
Accuracy drops caused by injecting specific error types into DeepSeek V3.2's reasoning chain on Bridges and Undead puzzles
Main Takeaways
- Constraint extraction is the bottleneck: providing structured tools improves accuracy by 10% on hard tasks, proving reasoning capability exists but is hampered by parsing
- Error frequency does not equal error impact: 'Constraint Forgetting' is rare in traces (4%) but causes massive accuracy drops when injected, whereas 'Repeated Reasoning' is common (33%) but benign
- Spatial parsing matters: changing input format to cell-aligned integers improves accuracy by 30-40pp on Bridges and Galaxies for some models
- Prompting strategies (planning, backtracking instructions) are ineffective at correcting these failures compared to format/tool changes