📝 Paper Summary
Personalized Assistant Benchmarking
User Simulation
LifeSim evaluates personalized assistants by simulating users with evolving internal cognitive states and realistic life trajectories, revealing that current models struggle with implicit intentions over long contexts.
Core Problem
Existing benchmarks for AI assistants rely on static, short-context datasets that fail to capture the complexity of real-world interactions where user needs evolve based on dynamic external environments and internal cognitive states.
Why it matters:
- Real-world user needs are shaped by temporal and situational contexts (e.g., location, weather), which static Q&A benchmarks cannot replicate
- Privacy constraints limit access to real long-term interaction logs, creating a blind spot in evaluating how models handle personal evolution over time
- Current evaluation methods overlook 'implicit intentions'—needs that are not explicitly stated but must be inferred from long-term history and habits
Concrete Example:
A user with a soy allergy asks 'Can you recommend a quick lunch?' A standard model might suggest a chicken salad with soy dressing. A personalized assistant should infer the implicit constraint from past history (the allergy) and current context (time/location) to recommend a compliant meal.
Key Novelty
Belief-Desire-Intention (BDI) Grounded User Simulation
- Models the user not just as a profile, but as a cognitive agent with a BDI architecture: 'Beliefs' (world view), 'Desires' (potential goals), and 'Intentions' (committed actions)
- Integrates an Event Engine that generates life trajectories (events like gym, work, dining) strictly grounded in real-world mobility data and Lewin’s equation (Behavior = f(Person, Environment))
Architecture
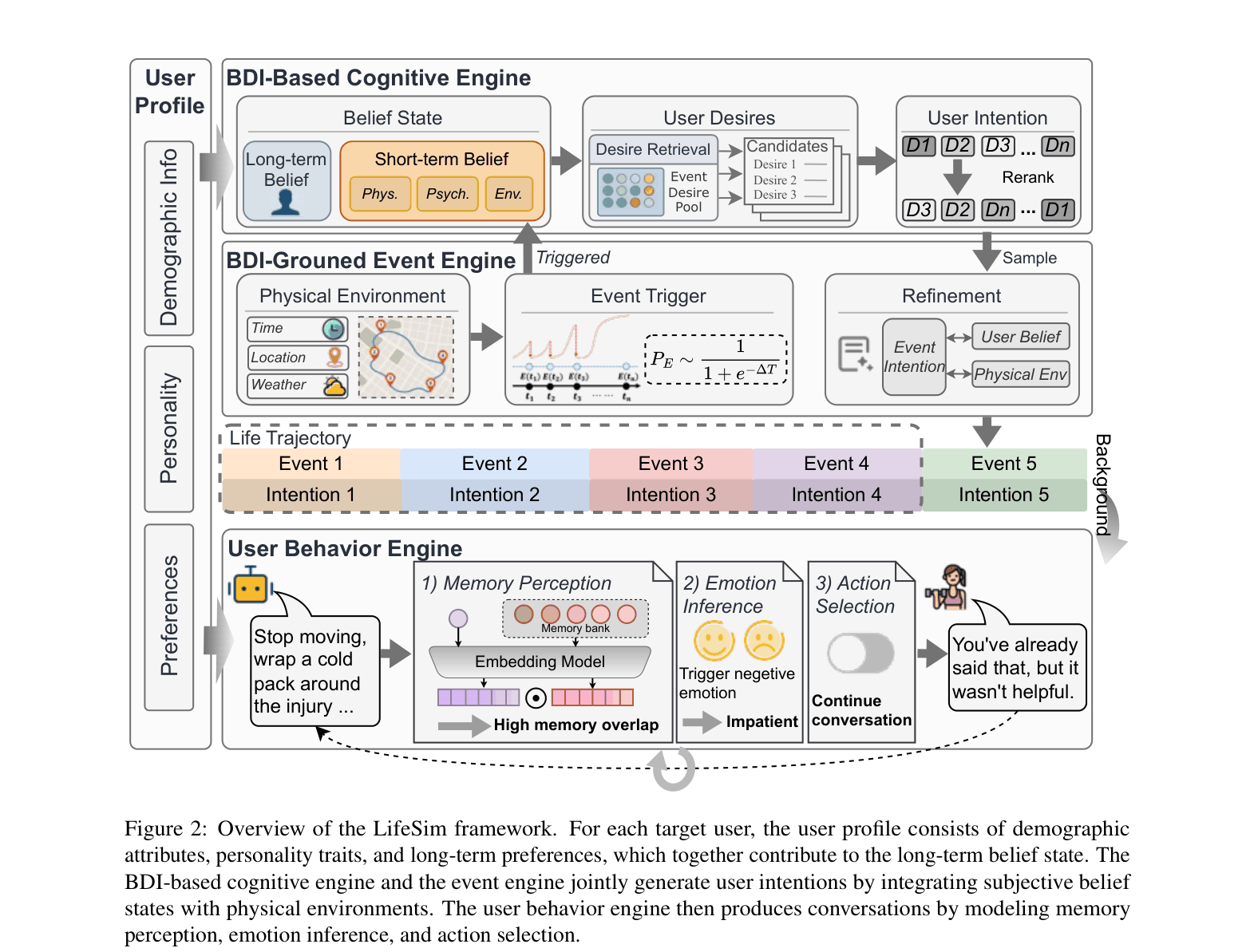
Overview of the LifeSim framework components and data flow
Evaluation Highlights
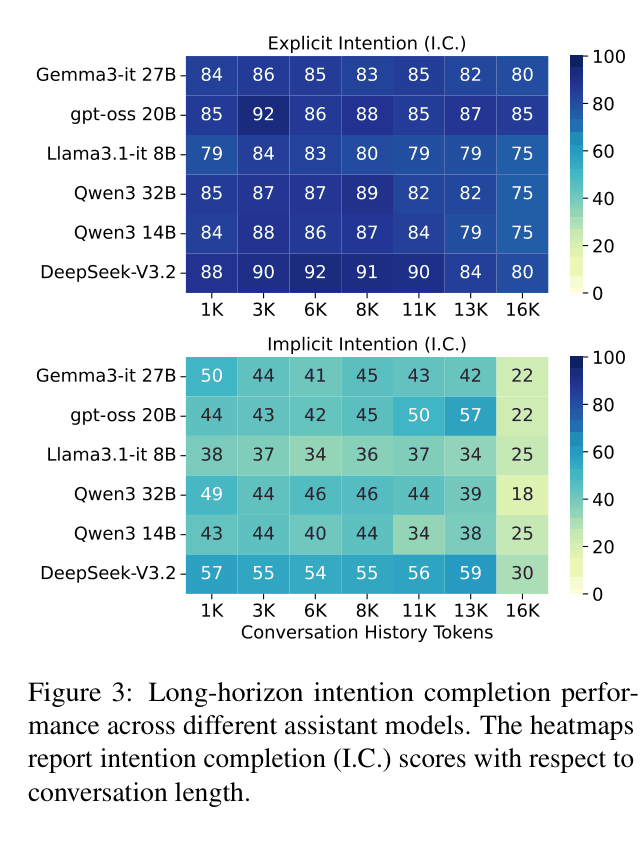
- GPT-5 shows a massive performance drop of 27.3 points between Explicit Intent Recognition (79.5) and Implicit Intent Recognition (52.2), highlighting a critical reasoning gap
- DeepSeek-V3.2 achieves the highest Persona Alignment score (75.5) among all models, outperforming GPT-4o (74.1) and Claude-Sonnet-4.5 (75.5)
- Long-horizon evaluation reveals that while Explicit Intention Completion remains stable (~85 for Qwen3 32B) as context grows to 16K tokens, Implicit Intention Completion degrades significantly (from 49 to 18)
Breakthrough Assessment
8/10
Proposes a highly sophisticated, cognitively grounded simulation framework that exposes significant weaknesses in state-of-the-art models regarding implicit reasoning, addressing a major gap in personalization benchmarks.