📊 Experiments & Results
Evaluation Setup
Fine-tuning a code LLM on selected synthetic data subsets
Benchmarks:
- HumanEval (Python Code Generation)
- HumanEval+ (Python Code Generation (Enhanced Tests))
- MBPP (Python Code Generation)
- MBPP+ (Python Code Generation (Enhanced Tests))
Metrics:
- Pass@1
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparison of QAQ (RMI-based selection) against full data training and baselines using 25% of the data. | ||||
| HumanEval+ | Pass@1 | 72.56 | 72.56 | 0.00 |
| HumanEval+ | Pass@1 | 69.51 | 72.56 | +3.05 |
| MBPP+ | Pass@1 | 56.61 | 58.47 | +1.86 |
| Ablation studying the impact of using model disagreement (Diff) vs consensus (Sum) for selection. | ||||
| HumanEval+ | Pass@1 | 68.90 | 71.95 | +3.05 |
| HumanEval+ | Pass@1 | 72.56 | 70.12 | -2.44 |
Experiment Figures
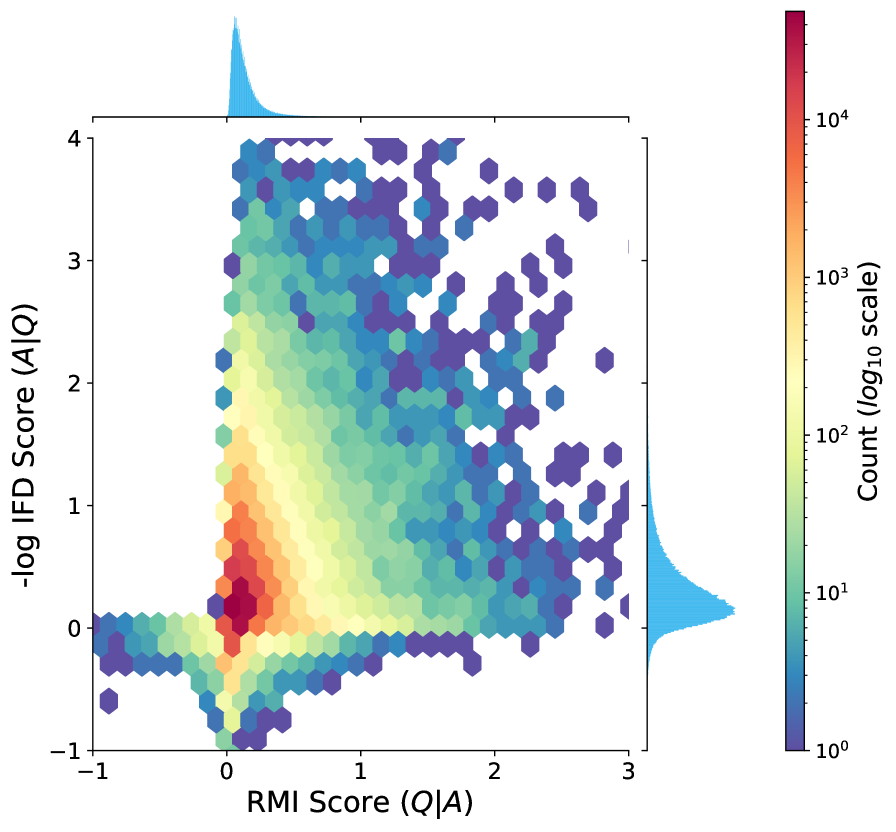
Scatter plot showing the correlation between RMI and IFD metrics
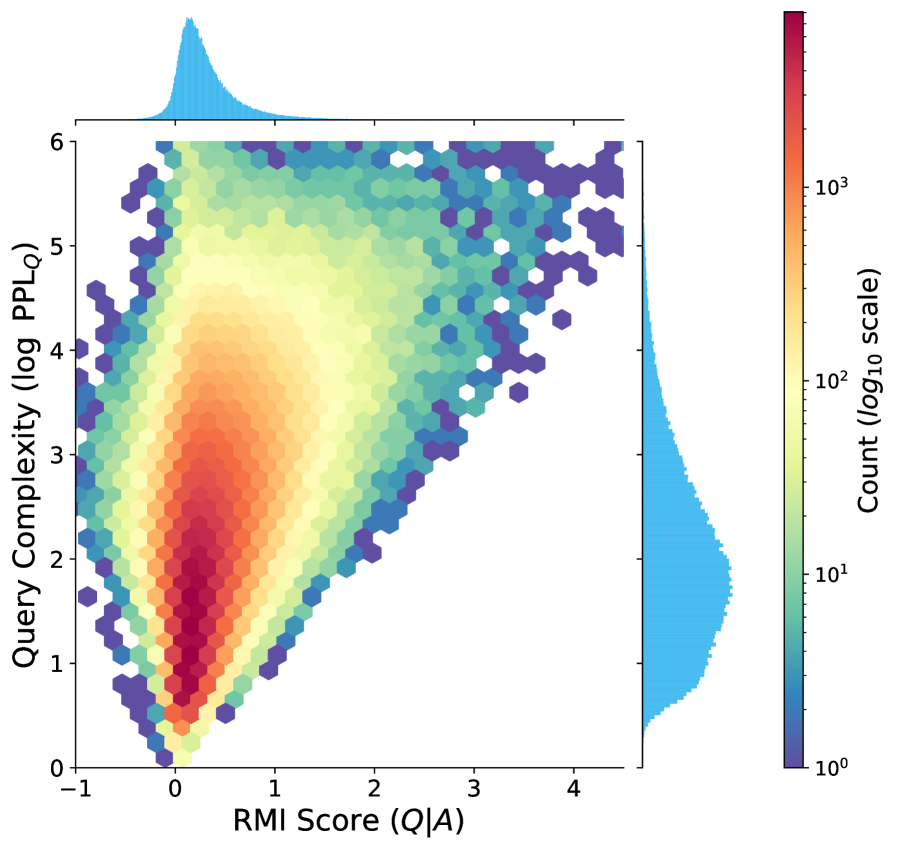
Scatter plot of RMI vs log PPL(Q) (Query Complexity)
Main Takeaways
- Both extremes of RMI are harmful: extremely low RMI indicates semantic misalignment (hallucinations), while extremely high RMI indicates trivial patterns (shortcuts/paraphrasing).
- The 'Sweet Spot' is the mid-to-high range (50-75%), or samples where models disagree (Cognitive Gap).
- Model disagreement is a strong signal for data efficiency: samples that are clear to a strong model but confusing to a weak model provide the best training signal.