📝 Paper Summary
Agentic RAG pipeline
Benchmark datasets
Document understanding
MADQA introduces a benchmark of 2,250 human-authored questions over heterogeneous PDFs to reveal that while current agents can match human accuracy, they rely on inefficient brute-force search rather than strategic planning.
Core Problem
Existing document QA benchmarks either lack visual complexity (text-only), are restricted to single domains (finance), or suffer from data integrity issues (LLM-generated questions, recycled documents), failing to test true agentic planning.
Why it matters:
- Businesses need agents to handle complex workflows over real-world PDFs (reports, contracts), not just plain text or single images
- Current evaluations conflate retrieval quality with generation skill and don't measure the 'cost' of reasoning
- There is a critical need to distinguish between agents that truly 'plan' and those that just randomly search until they get lucky
Concrete Example:
A user asks: 'Which lesson plan suggests a lower instructor ratio: Firearms or New Mexico Justice System?' An agent must retrieve two distinct documents, extract the ratios from potentially different page layouts, and compare them. Current agents often fail to stop searching after finding the answer, or get stuck in loops, wasting compute.
Key Novelty
MADQA: Multimodal Agentic Document QA Benchmark
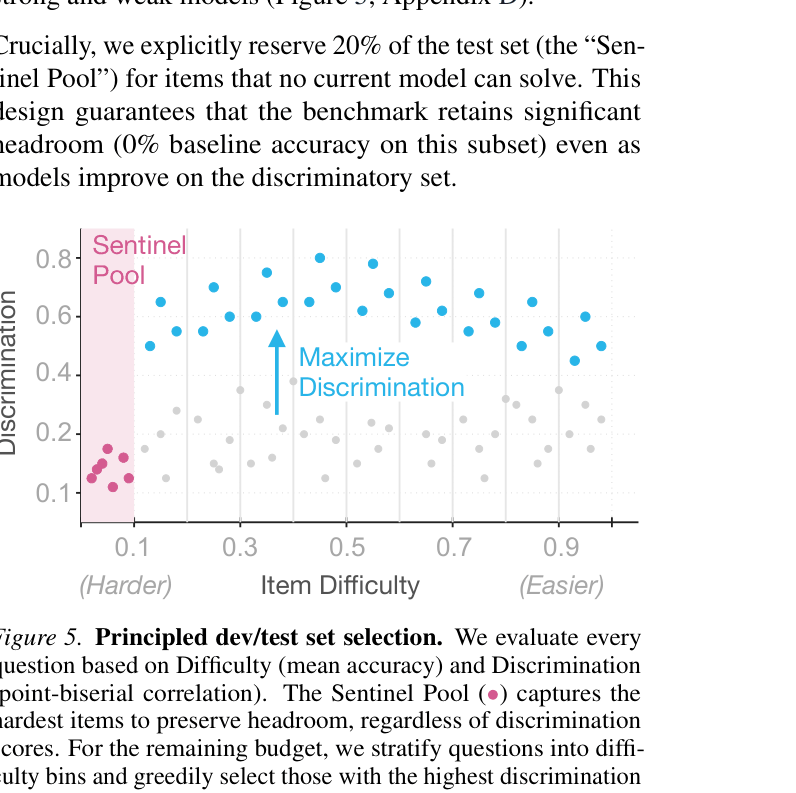
- A dataset of 2,250 questions over 800 fresh, heterogeneous PDFs, designed using Classical Test Theory to maximize discriminative power between model abilities
- A novel 'accuracy-effort trade-off' evaluation protocol using the Kuiper statistic to measure whether an agent's computational spend correlates with its success rate
- Strict 'agentic' design where questions require multi-hop reasoning across pages/docs that cannot be solved by a single retrieval query or external knowledge
Architecture
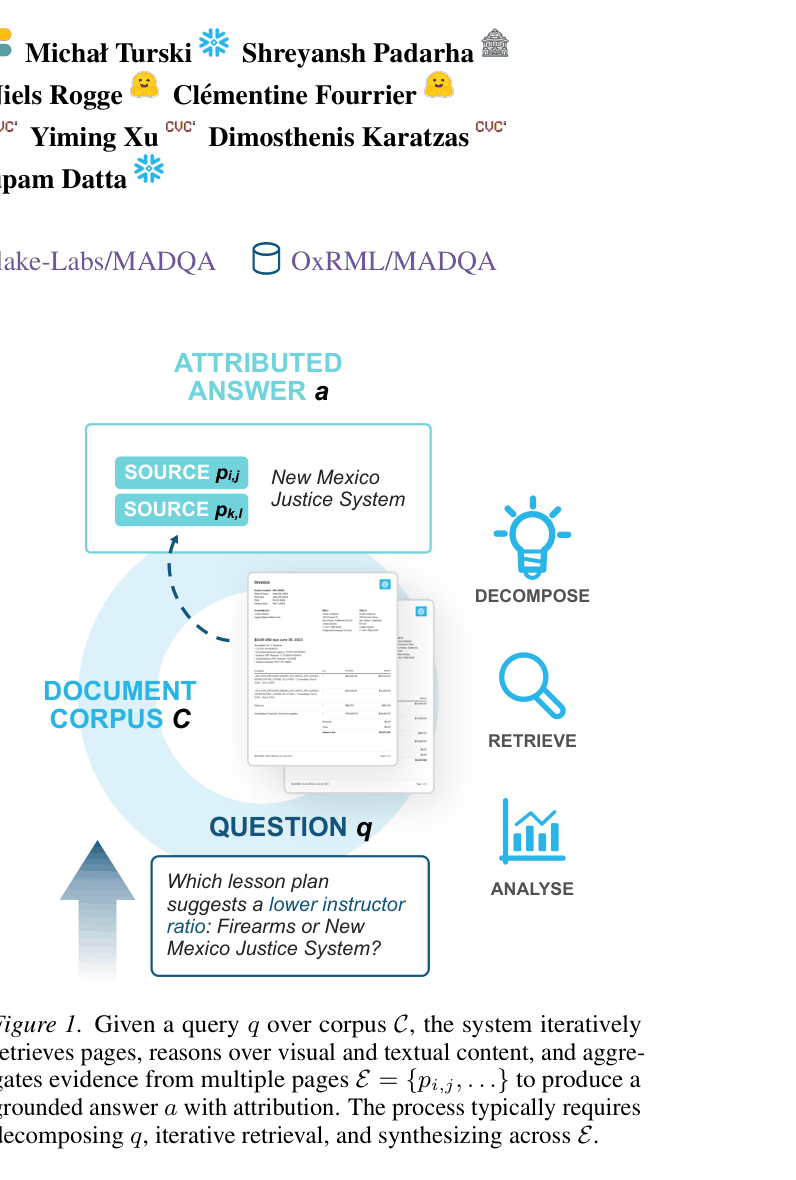
Conceptual workflow of the Agentic Document Collection QA task
Evaluation Highlights
- Gemini 3 Pro BM25 Agent achieves 82.2% accuracy, matching human search performance (82.2%) but lagging behind human oracle performance (99.4%)
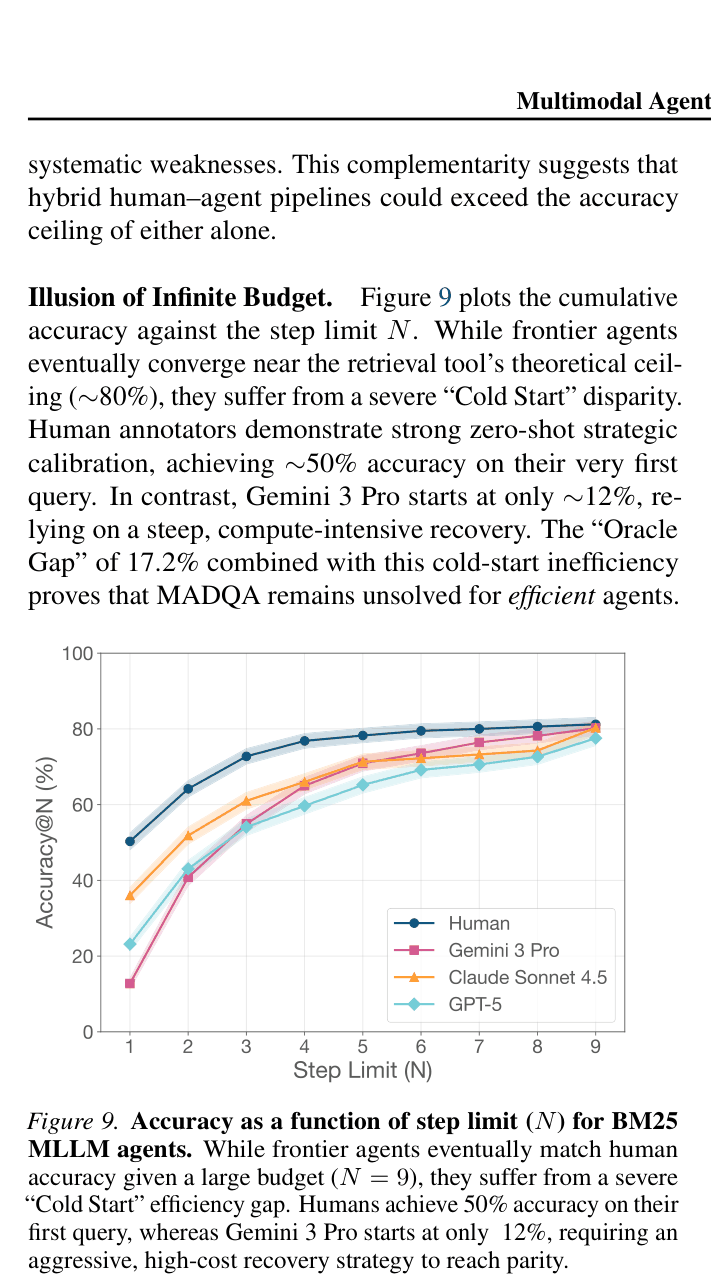
- Humans achieve 50% accuracy on their very first query (zero-shot calibration), while Gemini 3 Pro starts at ~12% and relies on expensive iterative recovery
- Simple agents with constrained search tools (BM25) outperform expensive, unconstrained Recursive Language Models (RLMs) while avoiding catastrophic cost overheads ($850 for one RLM run)
Breakthrough Assessment
9/10
Sets a new standard for agentic document benchmarking with rigorous human annotation and a novel focus on efficiency/calibration rather than just raw accuracy.