📝 Paper Summary
Efficient Inference
Sparse Attention
IndexCache accelerates sparse attention by running the expensive token selection mechanism on only a few anchor layers and reusing those indices for subsequent layers.
Core Problem
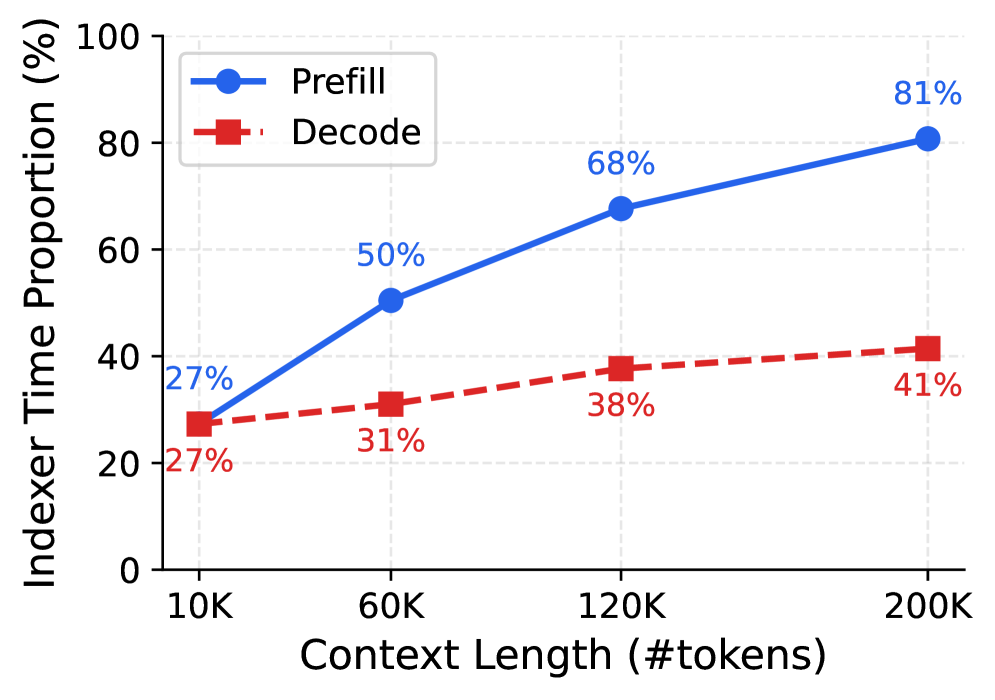
DeepSeek Sparse Attention (DSA) reduces core attention cost, but the 'lightning indexer' (token selector) still runs at quadratic complexity on every layer, dominating latency in long-context scenarios.
Why it matters:
- Long-context workflows (agents, RAG) are bottlenecked by attention costs, specifically the prefill latency which grows quadratically
- In sparse attention models, the selection mechanism (indexer) becomes a non-negligible cost fraction (O(NL^2)) even if core attention is efficient
- Existing methods optimize core attention but overlook the redundancy in the token selection step itself
Concrete Example:
In a 30B DSA model processing long context, the indexer must score all previous tokens at every single layer (1 to N). However, Layer 5 and Layer 6 often select 70-100% of the same tokens, meaning Layer 6's expensive indexer computation is largely redundant.
Key Novelty
Cross-Layer Index Reuse for Sparse Attention
- Partitions layers into 'Full' (retain indexer) and 'Shared' (reuse indices from previous Full layer), exploiting the observation that important tokens remain stable across adjacent layers
- Introduces a greedy layer selection algorithm (Training-free) to identify which layers must keep their indexers based on calibration loss
- Proposes multi-layer distillation (Training-aware) to train indexers to select tokens that are optimal for a cluster of subsequent layers, not just their own
Architecture
The inference workflow of IndexCache compared to standard DSA.
Evaluation Highlights
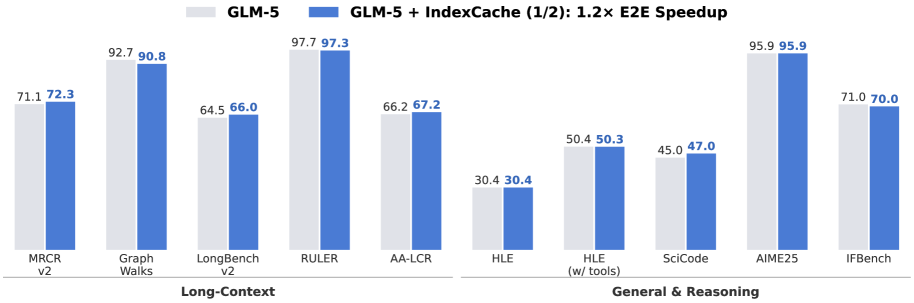
- Achieves up to 1.82x prefill speedup on a 30B DSA model at 200K context length compared to standard DSA
- Eliminates 75% of indexer computations (retaining only 1/4 of indexers) with negligible quality degradation across benchmarks
- Achieves 1.48x decoding speedup by skipping indexer computations in Shared layers
Breakthrough Assessment
7/10
Provides a practical, significant speedup for production-grade sparse attention (DSA) by addressing a specific quadratic bottleneck (the indexer). The combination of training-free and training-aware methods makes it versatile.