📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Diffusion Models
Chain-of-Thought Reasoning
EndoCoT enables diffusion models to perform multi-step chain-of-thought reasoning by iteratively refining latent states within the text encoder before guiding image generation, rather than relying on static single-step embeddings.
Core Problem
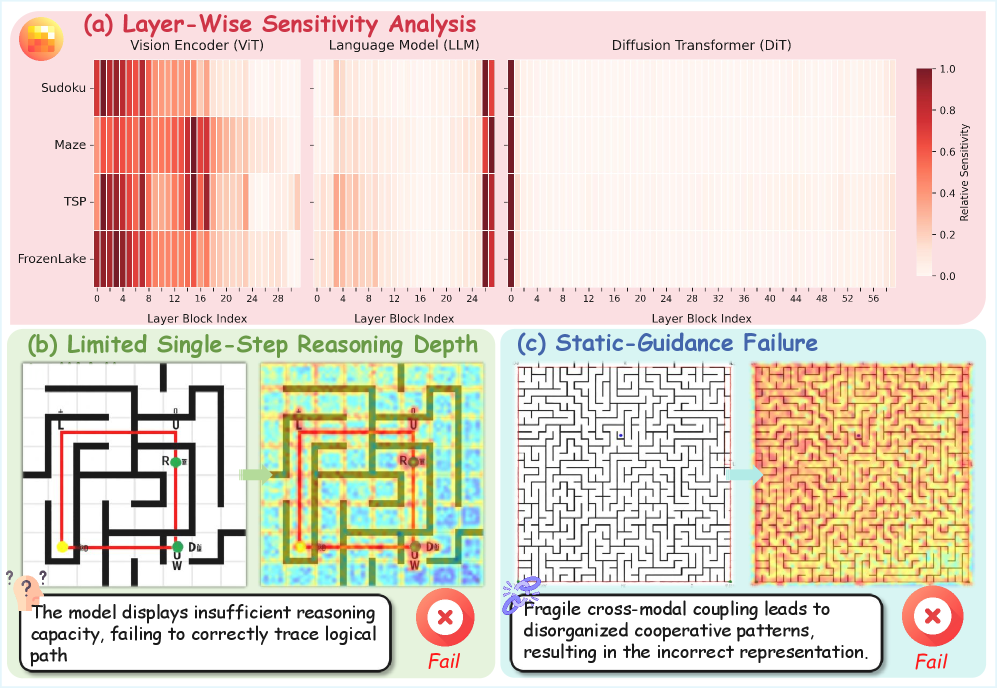
Current diffusion models use MLLMs as static text encoders that compute embeddings once, failing to activate chain-of-thought processes needed for complex multi-step reasoning tasks like mazes or spatial planning.
Why it matters:
- Static guidance prevents the model from decomposing complex instructions into actionable steps, leading to catastrophic failure in tasks requiring logical constraints
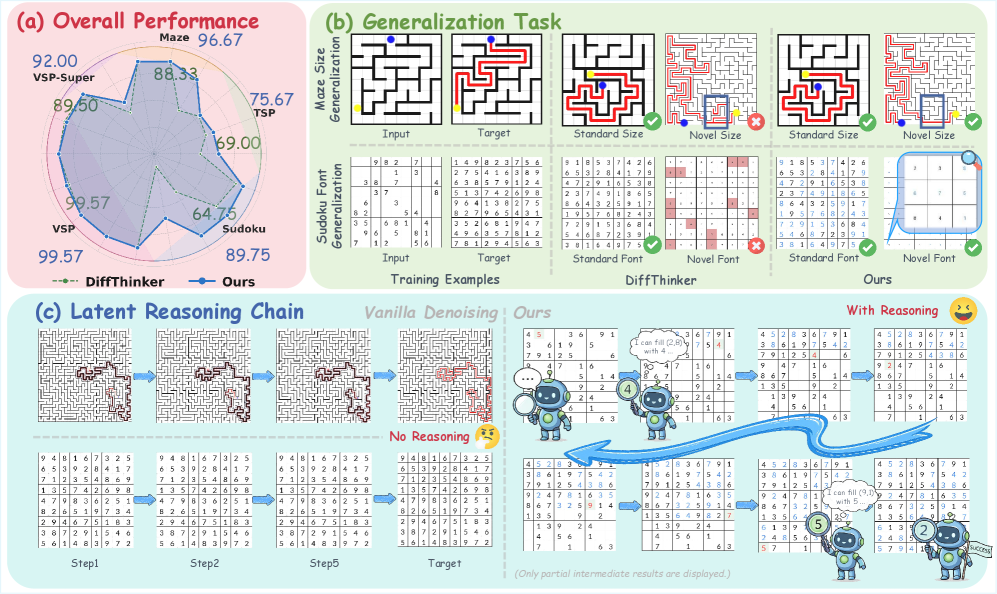
- Prior methods like DiffThinker inject reasoning externally but result in superficial alignment that breaks down on novel domains or complex topologies
- Without endogenous reasoning, diffusion models merely perform pattern matching rather than genuine cognitive processing, limiting their use in logical tasks
Concrete Example:
In a 32x32 maze generation task, a standard diffusion model generates a path that looks visually correct but passes through walls because the static text embedding cannot enforce the strict sequential constraints needed for a valid solution.
Key Novelty
Endogenous Chain-of-Thought (EndoCoT)
- Iterative Thought Guidance: recursively updates the MLLM's latent hidden states multiple times to simulate a chain-of-thought process before generation
- Terminal Thought Grounding: forces the final latent reasoning state to align with explicit textual supervision (the ground truth answer), anchoring the reasoning trajectory
- Joint fine-tuning of both the MLLM and Diffusion Transformer (DiT) to synchronize the dynamic reasoning states with the denoising process
Architecture
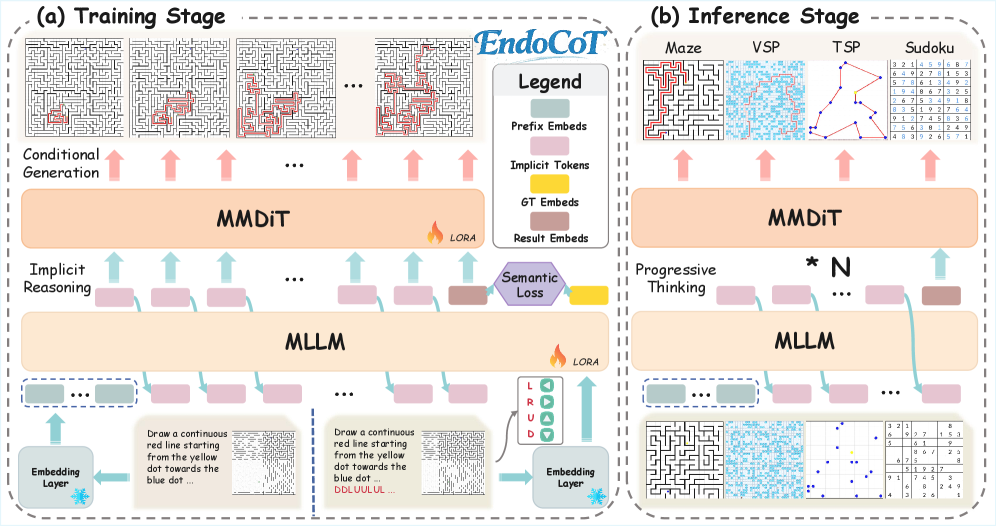
The EndoCoT framework illustrating the iterative reasoning loop and progressive training stages.
Evaluation Highlights
- Achieves 92.1% average accuracy across Maze, TSP, VSP, and Sudoku benchmarks, outperforming the strongest baseline by 8.3 percentage points
- Maintains 90% accuracy on complex Maze-32 tasks where baselines fail, outperforming the strongest baseline by 25%
- Achieves 95% accuracy on Sudoku-35, outperforming the strongest baseline by 40%
Breakthrough Assessment
8/10
Significant step forward in making diffusion models reason rather than just generate. The shift from static to dynamic/iterative conditioning addresses a fundamental bottleneck in spatial reasoning tasks.