📝 Paper Summary
Web agents
Planning benchmarks
Knowledge graph navigation
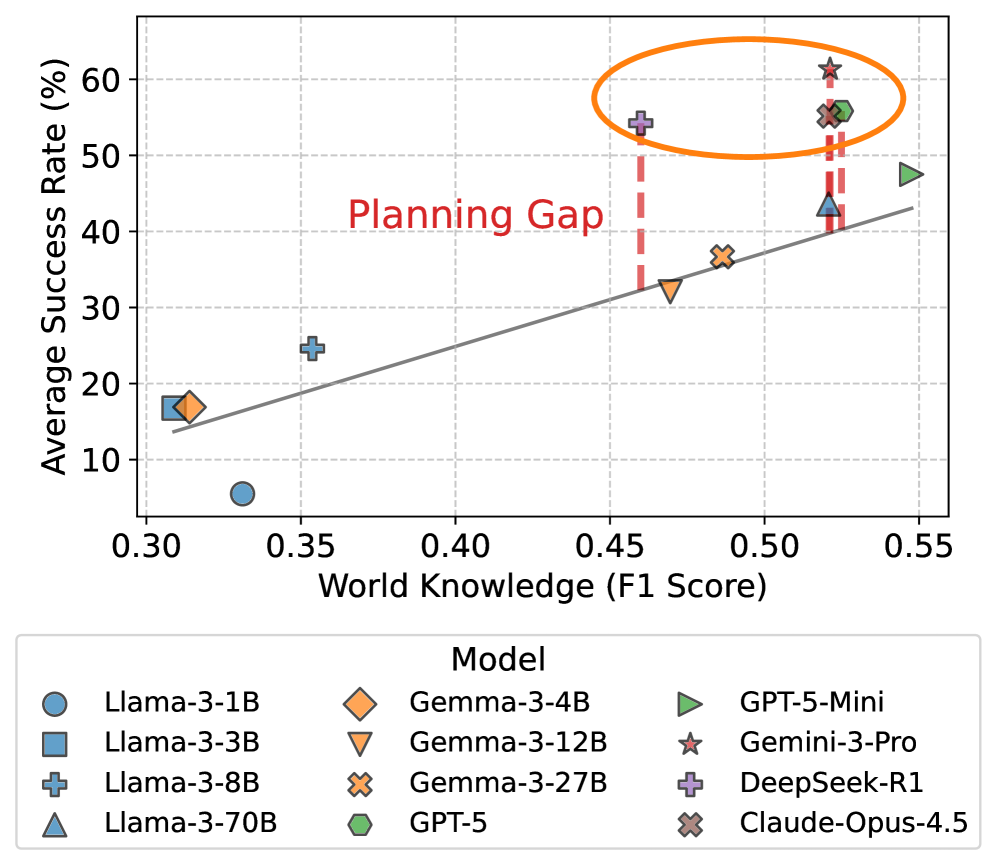
LLM-WikiRace forces agents to navigate Wikipedia step-by-step, revealing that even frontier models struggle with replanning and loop avoidance on hard tasks despite possessing sufficient world knowledge.
Core Problem
Existing planning benchmarks are typically synthetic or highly structured (e.g., Blocksworld), failing to test how LLMs leverage world knowledge to reason and replan in large, partially observable real-world environments.
Why it matters:
- Synthetic environments do not capture the semantic richness and uncertainty of real-world information spaces
- Current evaluations mask the distinction between having knowledge (memorization) and using it operationally for multi-step navigation
- Frontier models show a 'planning gap' where strong knowledge does not translate to success in long-horizon tasks requiring error recovery
Concrete Example:
In a Hard difficulty game (path length 7-8), Gemini 3 often identifies a 'hub-seeking' strategy but gets stuck in a loop visiting the same pages repeatedly, failing to revise its plan despite explicitly noting the repetition in its reasoning trace.
Key Novelty
LLM-WikiRace Benchmark
- Adapts the 'WikiRace' game into an interactive agent benchmark where models must navigate Wikipedia hyperlinks to reach a target page without seeing the full graph
- Decouples 'world knowledge' from 'planning ability' by comparing navigation success against a direct graph-connectivity classification task
- Identifies a 'planning gap' where models with comparable knowledge fail due to specific behavioral flaws like inability to recover from loops
Architecture
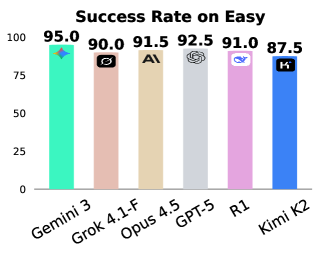
Illustration of the WikiRace task structure and the agent-environment interaction loop.
Evaluation Highlights
- Gemini 3 achieves <23% success on the Hard split (path length 7-8) compared to >90% on the Easy split, showing current models fail at long horizons
- Looping frequency has a strong negative correlation (regression coefficient -1.02) with success rate, identifying replanning failure as a primary bottleneck
- Fine-tuning with DAPO improves success on Easy tasks (+45.0% for Qwen-2.5-7B) but yields 0% improvement on Hard tasks
Breakthrough Assessment
8/10
Provides a realistic, non-synthetic planning benchmark that exposes clear failures (loops) in frontier models (GPT-5, Gemini 3) that standard benchmarks miss.