📝 Paper Summary
Reinforcement Learning for LLM Agents
Sparse Reward Optimization
HCAPO enables efficient training of long-horizon LLM agents by using the model itself to retrospectively verify which intermediate actions were necessary for a successful outcome, refining sparse rewards.
Core Problem
Existing value-free RL methods like GRPO fail in long-horizon tasks because they assign the same sparse terminal reward to every action in a trajectory, unable to distinguish critical decisions from irrelevant ones.
Why it matters:
- Long-horizon tasks (e.g., web navigation, embodied planning) often have only a single success/fail signal at the very end, leaving intermediate steps unguided.
- Current methods rely on global baselines that are misaligned with evolving intermediate states, leading to high variance and inefficient exploration.
- Alternative solutions like Process Reward Models require expensive human annotation, restricting scalability.
Concrete Example:
In a WebShop task, an agent might search, browse five irrelevant items, click the correct item, and buy it. GRPO rewards the irrelevant browsing equally to the purchase. HCAPO looks back from the success to identify that only the search and purchase were pivotal.
Key Novelty
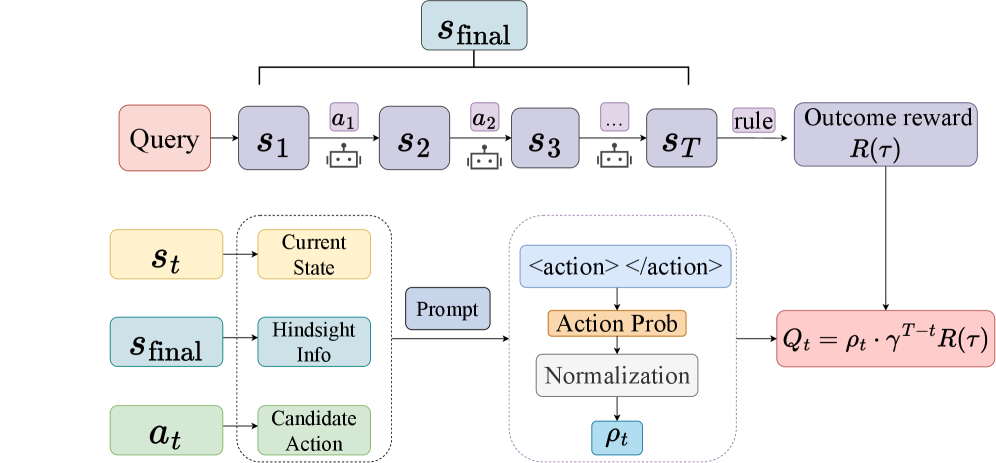
Hindsight Credit Assignment Policy Optimization (HCAPO)
- Generative Verification: Uses the LLM as a 'post-hoc critic' by prompting it with the successful outcome to estimate the probability of previous actions, amplifying credit for those that were causally necessary.
- Self-Normalized Importance Sampling: Estimates the ratio between hindsight and policy probabilities using intra-trajectory normalization, avoiding the need for training a separate external critic model.
- Multi-Scale Advantage: Combines robust trajectory-level outcome signals (macro) with fine-grained step-level hindsight signals (micro) to stabilize training while targeting bottlenecks.
Architecture
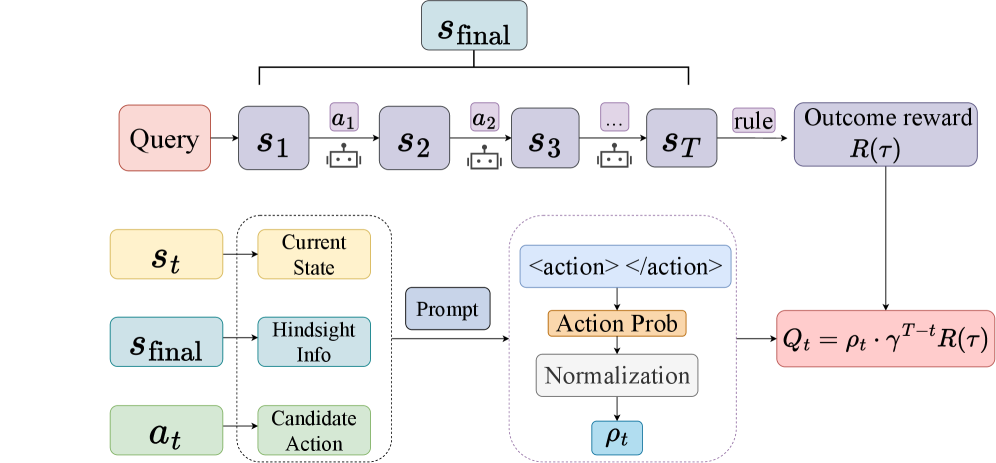
The overall framework of HCAPO, illustrating the separation of trajectory generation and the subsequent hindsight credit assignment process.
Evaluation Highlights
- +13.8% improvement in success rate on ALFWorld over GRPO using Qwen2.5-7B-Instruct (77.6% -> 91.4%).
- +7.7% improvement in success rate on WebShop over GRPO using Qwen2.5-7B-Instruct (66.1% -> 73.8%).
- Achieves 96.9% success rate on ALFWorld with temporal smoothing, nearing perfect performance.
Breakthrough Assessment
8/10
Significantly advances value-free RL for agents by solving the credit assignment problem without external reward models, showing large empirical gains on standard benchmarks.