📝 Paper Summary
Knowledge Distillation
On-Policy Learning
Reasoning
EOPD improves on-policy distillation by dynamically switching from reverse KL to forward KL when the teacher's entropy is high, preserving crucial diversity in complex reasoning tasks.
Core Problem
Standard on-policy distillation uses reverse KL divergence, a mode-seeking objective that forces the student to collapse onto a single path even when the teacher is uncertain.
Why it matters:
- High-entropy tokens in reasoning tasks often represent valid alternative paths or necessary uncertainty; collapsing them degrades reasoning capability
- Reverse KL provides unstable gradient signals when the teacher distribution is flat or multi-modal, preventing proper convergence
- Current methods achieve efficiency but lose the distributional richness of the teacher, leading to worse performance on complex benchmarks
Concrete Example:
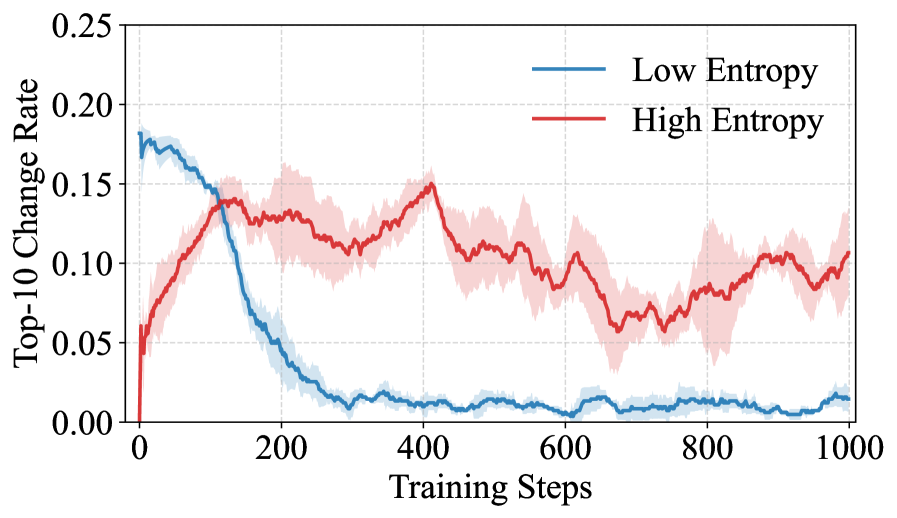
In a toy experiment where a teacher has a high-entropy distribution (spread across multiple modes), a student trained with reverse KL exhibits unstable oscillating predictions (frequent top-1 changes) and fails to cover the valid modes, whereas the teacher retains 18.5% high-entropy tokens compared to the student's 6.8%.
Key Novelty
Entropy-Aware On-Policy Distillation (EOPD)
- Dynamically switches the loss function based on the teacher's token-level entropy: uses standard reverse KL for confident low-entropy tokens to maintain efficiency
- Activates forward KL for high-entropy tokens to force the student to cover the teacher's full distribution (mode-covering), preserving diversity where uncertainty exists
Architecture
The training loop for Entropy-Aware On-Policy Distillation
Evaluation Highlights
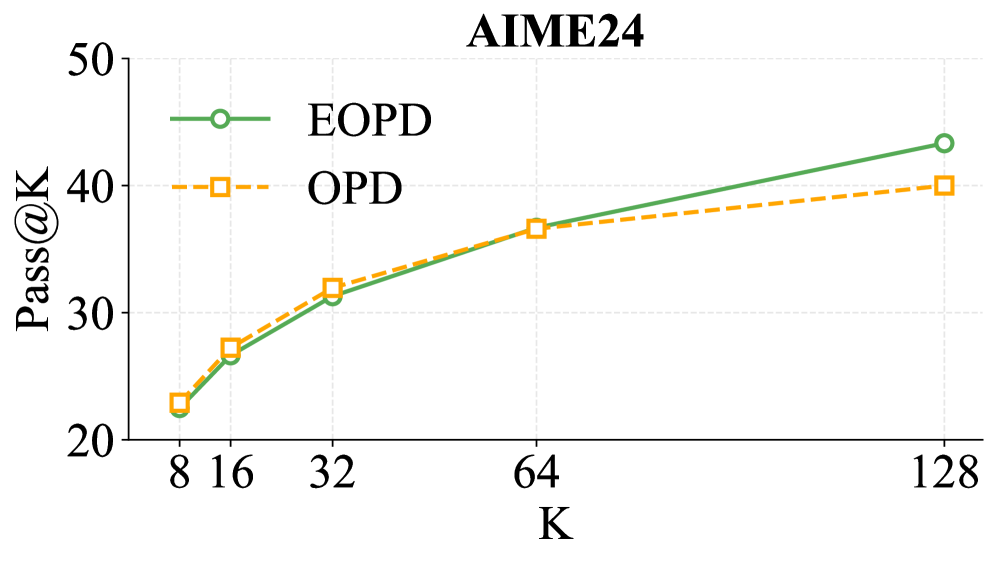
- +5.05 Pass@8 improvement on average across six math benchmarks for Qwen3-4B-Base compared to standard on-policy distillation
- +2.39 Pass@8 improvement for Qwen3-1.7B-Base on the same benchmarks
- Retains significantly more high-entropy tokens than baselines, successfully transferring the teacher's uncertainty structure
Breakthrough Assessment
7/10
Solid methodological improvement identifying a specific failure mode of reverse KL (diversity collapse) and proposing a principled, effective fix. Consistent gains across model sizes.