📊 Experiments & Results
Evaluation Setup
Image classification on non-IID data partitions.
Benchmarks:
- CIFAR-10 (Image Classification)
- CINIC-10 (Image Classification)
- Tiny-ImageNet (Image Classification)
- EMNIST (Handwritten Character Recognition)
Metrics:
- Top-1 Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Performance on highly non-IID data (Dirichlet alpha=0.1) shows pFedSim consistently outperforming baselines. | ||||
| Tiny-ImageNet | Accuracy | 57.28 | 64.91 | +7.63 |
| EMNIST | Accuracy | 95.12 | 95.70 | +0.58 |
| CINIC-10 | Accuracy | 84.30 | 84.34 | +0.04 |
| Performance on moderately non-IID data (Dirichlet alpha=0.5). | ||||
Experiment Figures

CKA (Centered Kernel Alignment) similarity heatmaps for different layers of LeNet5 trained on non-IID data.
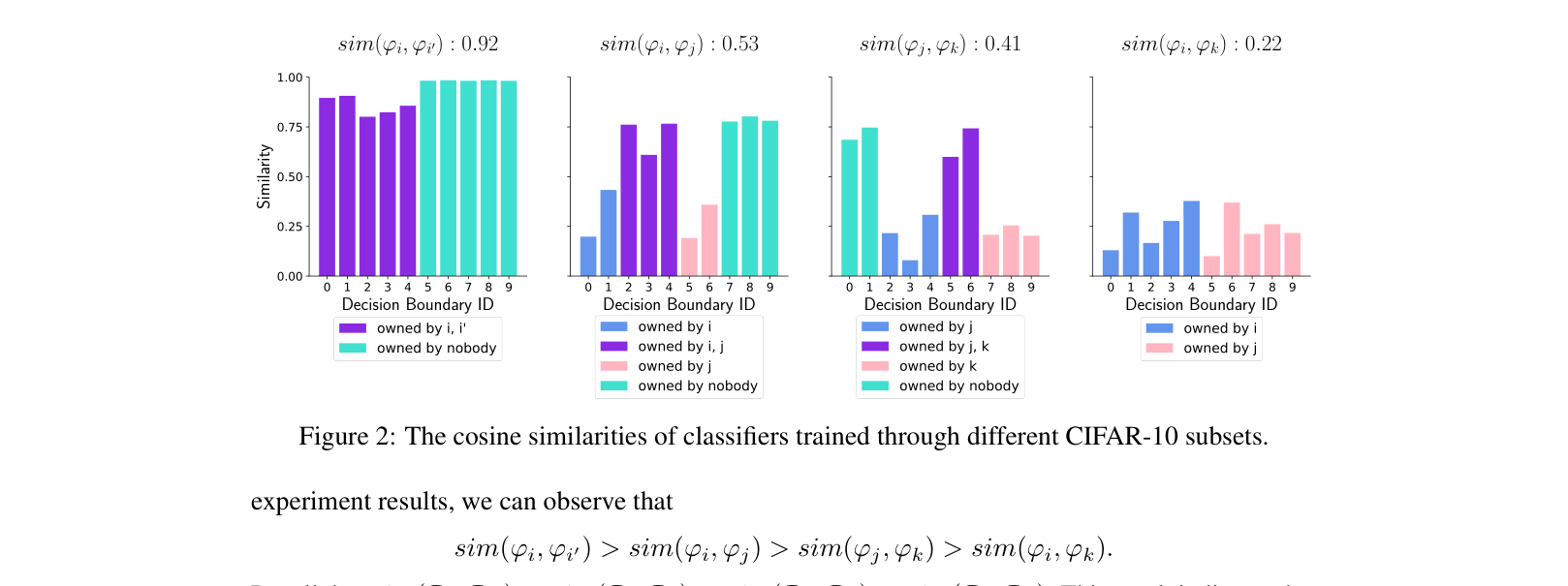
Cosine similarities of classifiers trained on different CIFAR-10 subsets with varying degrees of label overlap.
Main Takeaways
- pFedSim consistently outperforms standard FL (FedAvg, FedProx) and state-of-the-art pFL methods (FedRep, FedPer, FedAP) across various non-IID settings.
- The method is particularly effective on complex datasets like Tiny-ImageNet, showing gains of ~7-10% over strong baselines.
- Classifier-based similarity is empirically shown to be a better proxy for data similarity than batch-norm statistics (WDB) or loss-based metrics (LDB).
- Robust to hyperparameter $\rho$ (generalization ratio) choices within the range [0.3, 0.7], with $\rho=0.5$ generally being optimal.