📝 Paper Summary
Personalized Federated Learning
Decentralized Learning
Knowledge Distillation
KD-PDFL enables decentralized clients to personalize models by measuring peer similarity through logit-based knowledge distillation on local data, eliminating the need for central servers or public proxy datasets.
Core Problem
In decentralized federated learning, clients must identify similar peers to collaborate effectively, but measuring similarity without sharing private data or assuming a central server is difficult.
Why it matters:
- Standard global models fail for clients with highly non-i.i.d. data distributions or unique preferences
- Existing decentralized methods often compromise privacy by exchanging class label information or requiring public proxy datasets
- Clients with small local datasets struggle to evaluate peer relevance accurately, leading to poor model convergence
Concrete Example:
In an IoT device classification task with non-i.i.d. data, a user with only 15 samples cannot effectively train a local model. If they use standard FedAvg, their model gets corrupted by irrelevant updates from dissimilar peers. KD-PDFL allows them to identify and weight only relevant peers based on output similarity.
Key Novelty
Distillation-based Peer Selection (KD-PDFL)
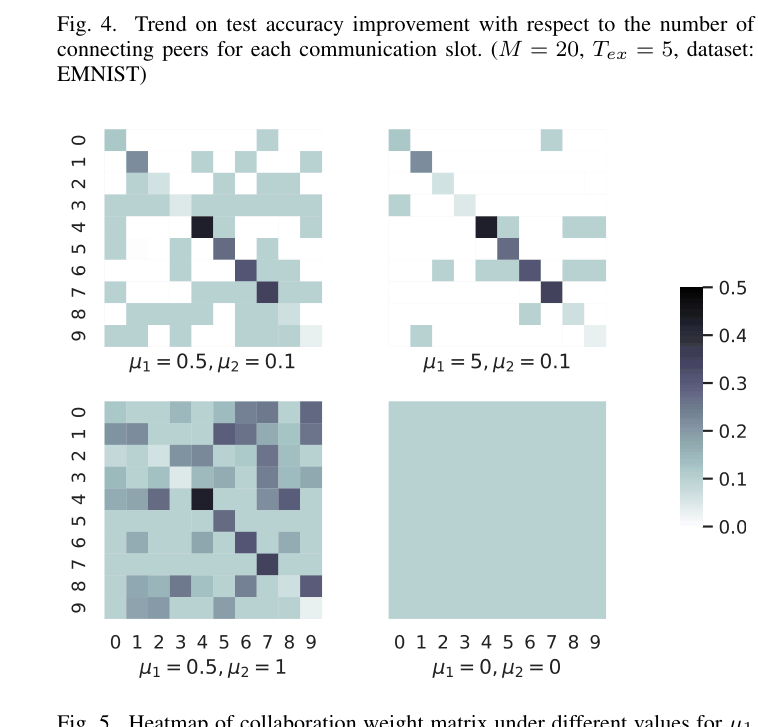
- Clients evaluate the relevance of neighbors by feeding their own local data into neighbors' received models and comparing the output logits via Wasserstein distance
- This metric acts as a weight for aggregating neighbor models, allowing purely local, autonomous decisions on who to collaborate with
- Eliminates the need for shared public datasets or direct label sharing found in prior personalized decentralized approaches
Architecture
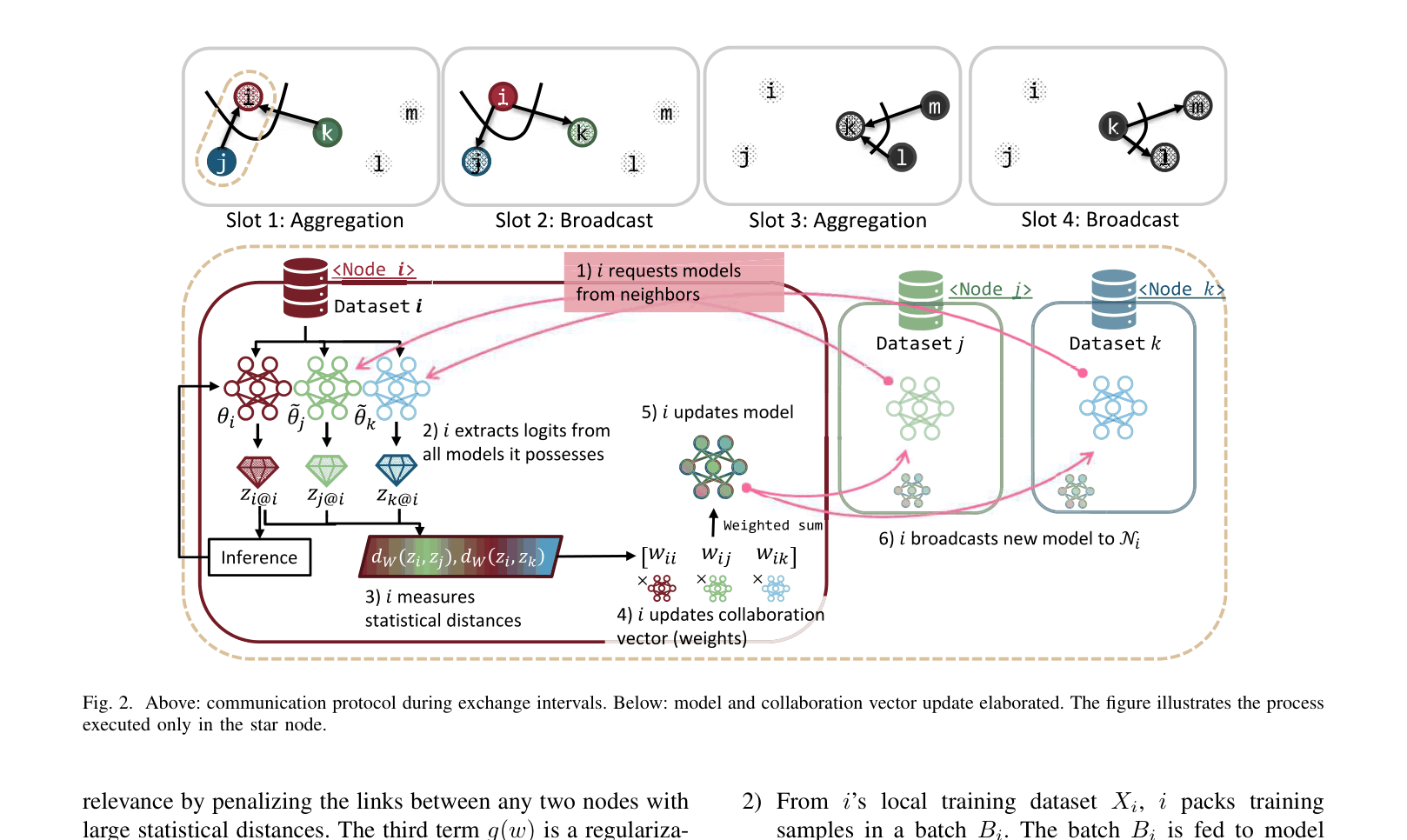
The communication and update protocol for a Star Node (center) interacting with neighbors.
Evaluation Highlights
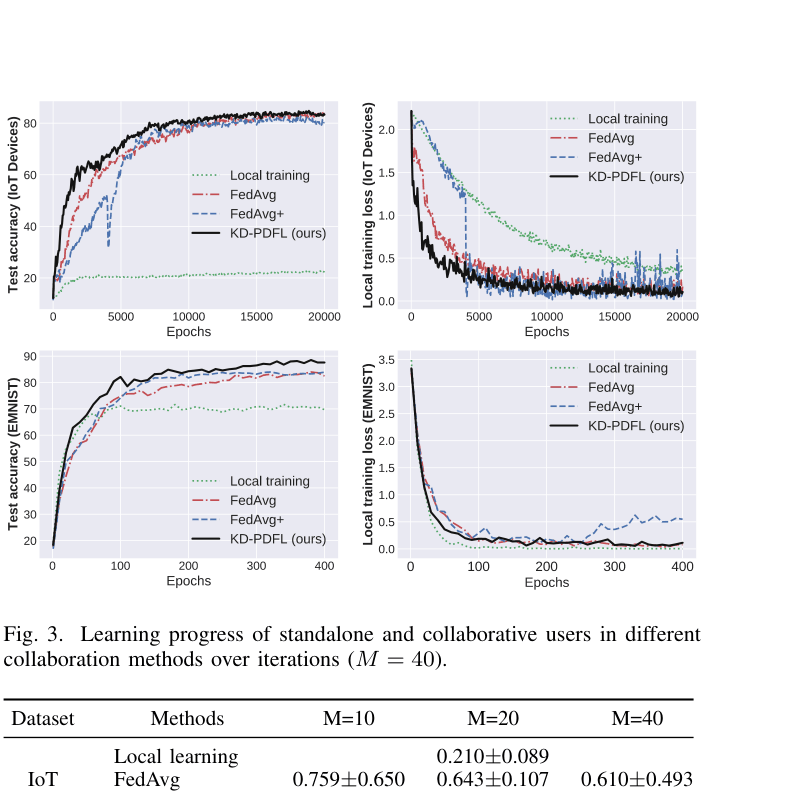
- Achieves 81.6% test accuracy on IoT devices dataset with small local data (15-100 samples), significantly outperforming local learning (21.0%)
- Surpasses standard FedAvg (61.0%) and FedAvg+ (69.7%) in test accuracy under highly non-i.i.d. settings with 40 participating clients
- Demonstrates faster convergence in fewer global iterations compared to FedAvg+ while maintaining higher accuracy
Breakthrough Assessment
6/10
Solid contribution to decentralized FL by removing the need for public proxy data using distillation. While the core mechanics are an application of known techniques (KD + FL), the fully autonomous peer-weighting protocol is valuable for privacy-sensitive edge networks.