📝 Paper Summary
Long-context LLMs
Attention mechanisms
The paper identifies 'contextual heads' that control attention to relevant information in long contexts and proposes 'focus directions'—vectors added to key/query activations—to steer these heads toward relevant contexts without external labels.
Core Problem
Long-context LLMs often get distracted by irrelevant information within their large context windows, leading to incorrect answers or hallucinations, and the specific attention mechanisms causing this are poorly understood.
Why it matters:
- Distraction in long-context tasks (like RAG or summarization) causes models to generate false information or erroneous reasoning despite having the correct answer in context.
- Current methods often rely on external labels or retraining to fix this, whereas understanding the internal mechanism could allow for inference-time correction.
Concrete Example:
In a multi-document QA task with 20 documents where only one is relevant, the model might fail to answer correctly because its attention heads pay equal or more attention to the 19 irrelevant documents (distractors) rather than the single relevant one.
Key Novelty
Focus Directions for Contextual Heads
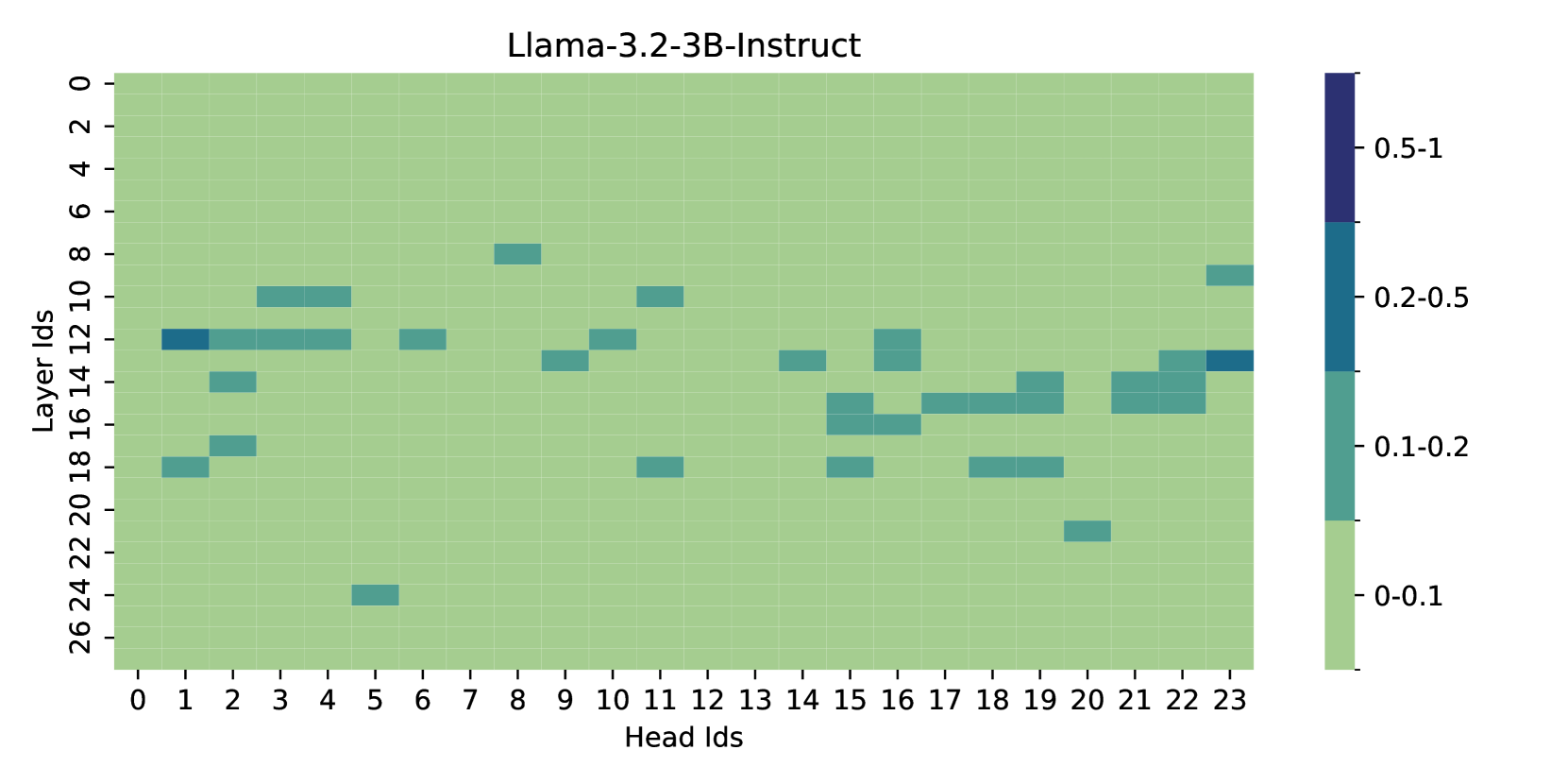
- Identifies a sparse set of 'contextual heads' that are primarily responsible for focusing on relevant information during generation.
- Discovers 'focus directions' in the key and query activation spaces of these heads; adding these vectors at inference time forces the model to attend more to relevant contexts without needing ground-truth labels.
Architecture
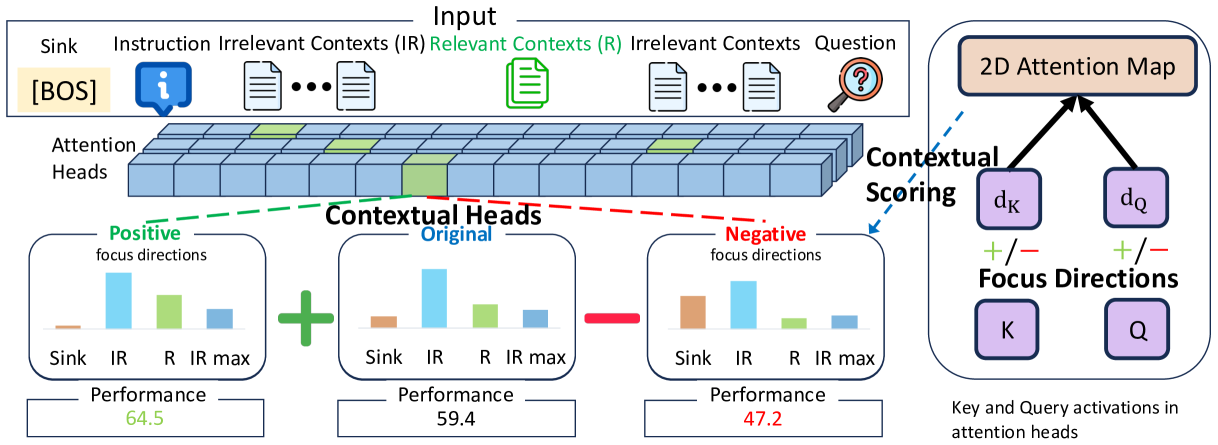
Conceptual workflow: (1) Measuring attention to identify contextual heads using labeled data, (2) Training focus directions (vectors) on Key/Query activations, and (3) Injecting these directions at inference to boost attention to relevant contexts.
Evaluation Highlights
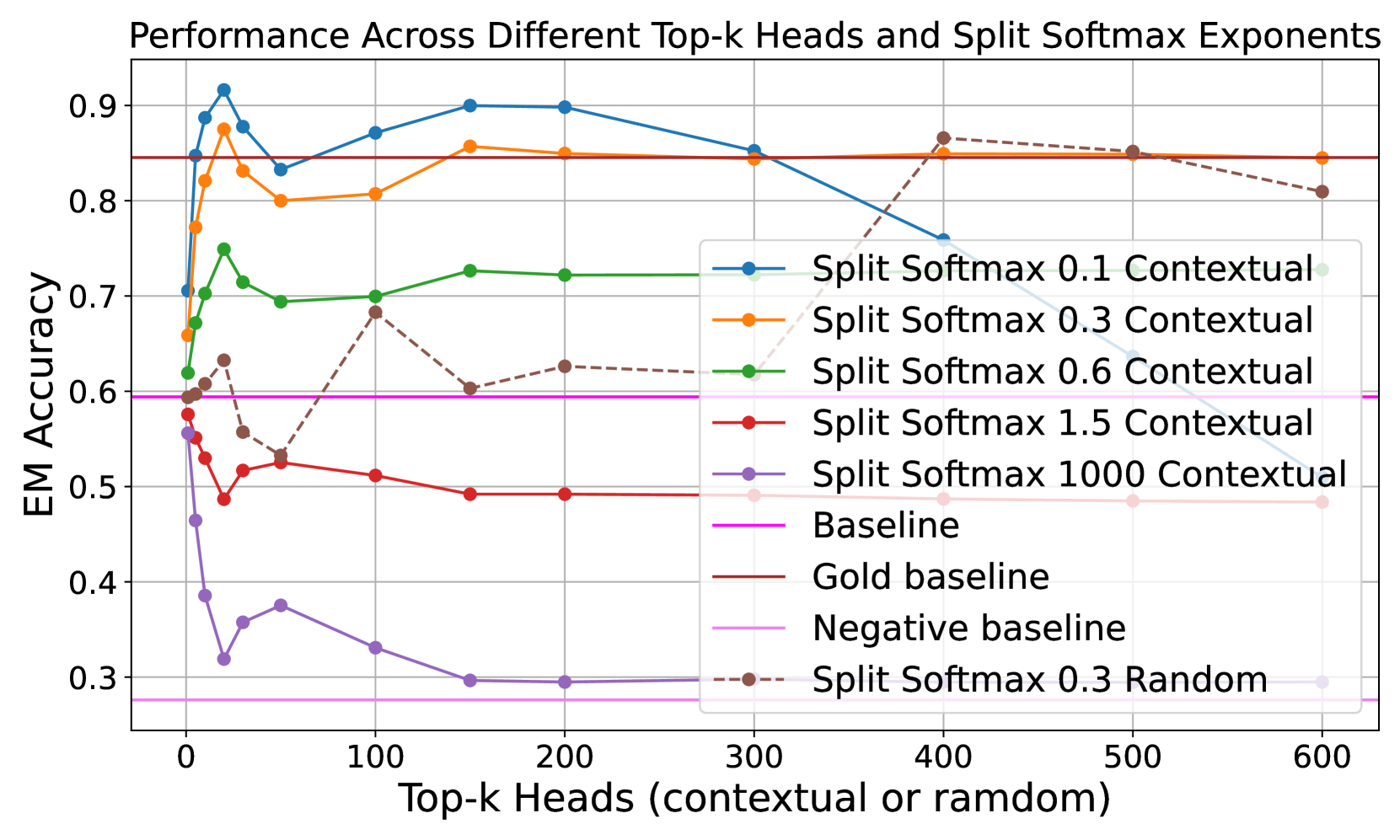
- +7.7% Exact Match accuracy improvement (from 59.4% to 67.1%) on a multi-document QA task by applying focus directions to the top-20 contextual heads.
- Demonstrates that intervening on just 20 'contextual heads' (out of 672) is more effective than intervening on random heads, verifying the sparsity and specificity of the mechanism.
- Shows that 'negative' focus directions (subtracting the vector) drastically reduce performance (down to ~32%), confirming these directions control the attention intensity.
Breakthrough Assessment
7/10
Provides a strong mechanistic explanation for long-context distraction and a novel inference-time intervention (focus directions) that improves performance without retraining, though tested primarily on one specific QA format.