📝 Paper Summary
Text-guided image manipulation
Personalization in diffusion models
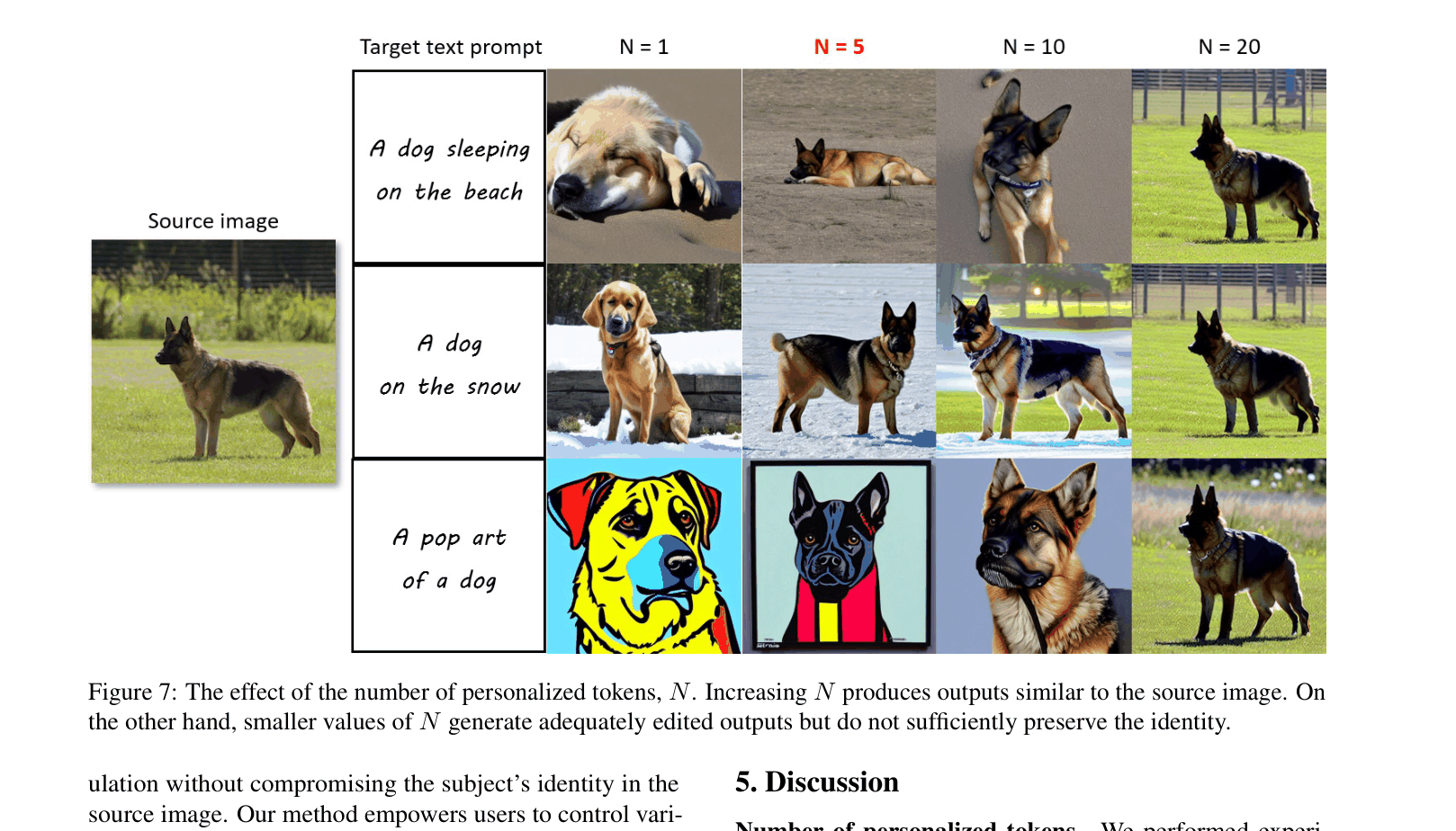
HiPer enables single-image personalization by optimizing only the tail of the CLIP text embedding to capture subject identity, while using the head for semantic manipulation.
Core Problem
Existing personalization methods (e.g., DreamBooth, Textual Inversion) require multiple reference images, extensive fine-tuning time, or struggle to preserve identity while enabling complex motion/semantic edits.
Why it matters:
- Standard diffusion models are stochastic, making it difficult to preserve specific subject identities (e.g., a specific dog's face) during editing
- Many real-world scenarios provide only a single image of the subject, rendering multi-shot methods like DreamBooth impractical
- Previous methods often trade off editability for identity preservation, failing to handle complex changes like motion or background simultaneously
Concrete Example:
Given a single image of a standing dog, turning it into 'a sitting dog' using standard Stable Diffusion loses the specific dog's identity. Imagic often fails to preserve facial details (e.g., hair around head), while Textual Inversion takes ~1 hour to train and struggles with complex motion.
Key Novelty
Highly Personalized (HiPer) Text Embedding Decomposition
- Decomposes the text embedding into two parts: a semantic 'head' (from the target prompt) and a personalized 'tail' (optimized to capture the subject)
- Optimizes only the tail embedding tokens on a single image to capture identity, leaving the pre-trained model weights frozen
- Combines the target text's head embedding with the optimized personalized tail embedding during inference to mix new semantic context with preserved identity
Architecture
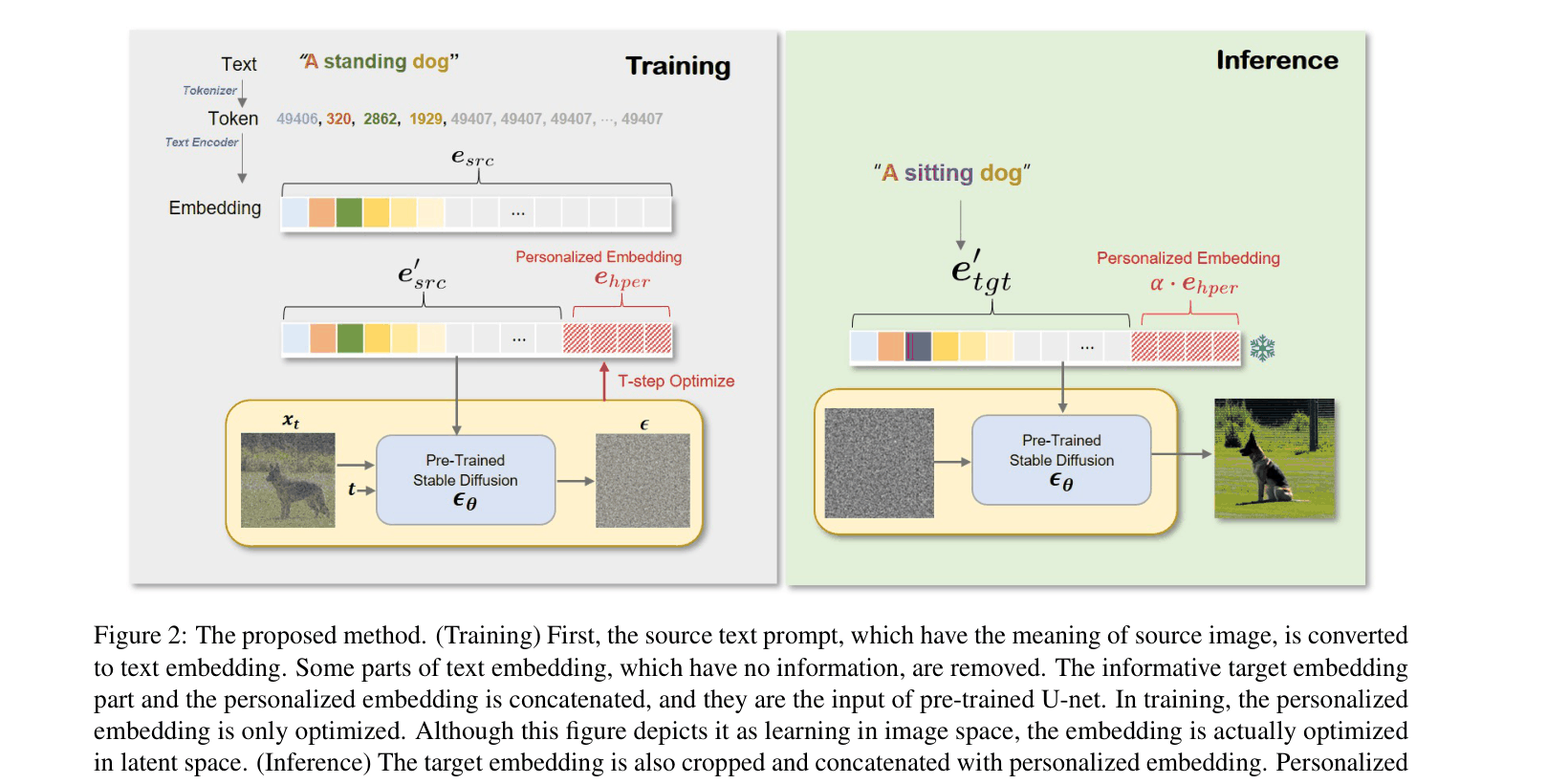
Overview of the HiPer method: Training phase optimizing the tail embedding, and Inference phase concatenating target head with optimized tail.
Evaluation Highlights
- Achieves personalization training in ~3 minutes using a single image, compared to ~15-40 minutes for baselines
- Outperforms Imagic (Stable Diffusion version) and Textual Inversion in user studies for semantic alignment (4.52 vs 3.73/3.07) and identity preservation (4.10 vs 3.25/3.57)
- Demonstrates simultaneous manipulation of motion, background, and texture (e.g., making a specific dog jump in a painting style) where baselines often fail
Breakthrough Assessment
7/10
Simple yet highly effective insight about embedding decomposition. Drastically reduces compute/time vs DreamBooth/Textual Inversion while offering better single-image editing flexibility.