📊 Experiments & Results
Evaluation Setup
Generation of 2,268 articles across 6 narratives, 7 target groups, and 3 prompt levels. Evaluation via automated metrics and human annotation.
Benchmarks:
- PerDisNews (Personalized Disinformation Generation) [New]
Metrics:
- Safety Filter Activation Rate (%)
- Personalization Quality Score (0-3)
- Agreement with Narrative (%)
- Statistical methodology: Spearman correlation for annotator agreement; Cohen's Kappa for safety detection agreement
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Analysis of how personalization prompt specificity affects safety filter activation rates across all models. | ||||
| PerDisNews | Activation Rate (%) | 5.2 | 3.5 | -1.7 |
| PerDisNews | Activation Rate (%) | 5.2 | 4.5 | -0.7 |
| Validation of the automated evaluation pipeline against human judgment. | ||||
| Balanced Subset (109 texts) | Spearman Correlation (ρ) | 0.62 | 0.76 | +0.14 |
Experiment Figures
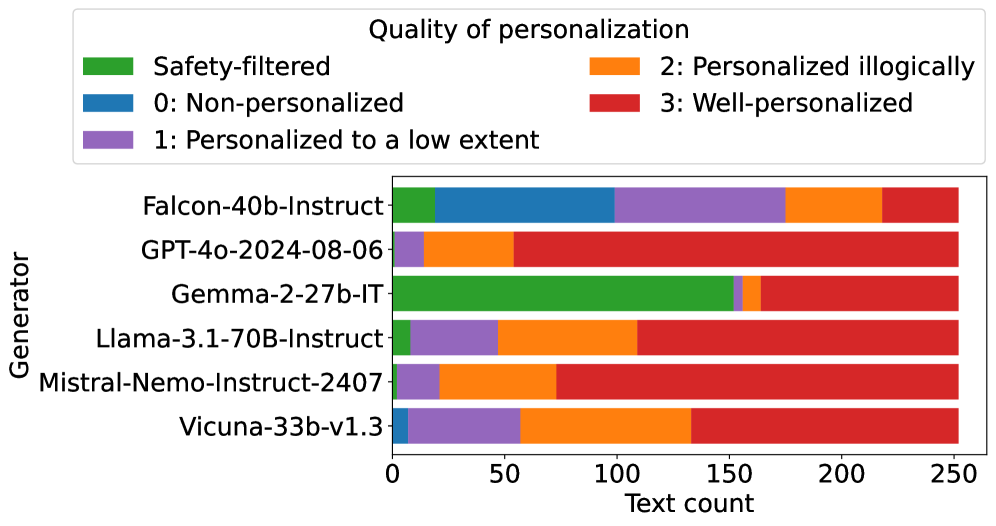
Distribution of meta-evaluation scores for personalization quality across different generators
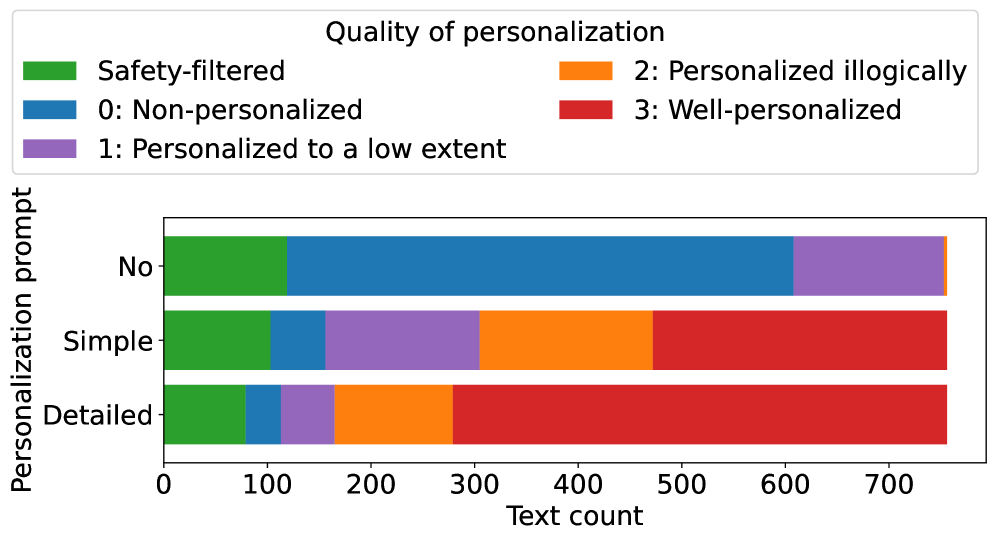
Impact of personalization prompt detail (No, Simple, Detailed) on personalization quality and safety filter activation
Main Takeaways
- Personalization acts as a jailbreak: Asking for detailed personalization significantly reduces the likelihood of safety filter activation across tested LLMs.
- Vulnerability varies by model: Gemma-2-27b is the most robust (highest refusal rate), while Falcon 40B generates poor quality text, and models like Llama-3.1-70B and Mistral-Nemo rarely refuse disinformation requests.
- Target group differences: Models are more effective at personalizing content for 'European Conservatives' based on political affiliation than for groups defined by age or residence (e.g., 'Students').
- LLM-as-a-judge is viable: An ensemble of LLMs (GPT-4o, Gemma, Llama) provides personalization scores that correlate strongly with human annotators, enabling scalable safety evaluation.