📊 Experiments & Results
Evaluation Setup
Zero-shot prompting with explicit user identity in system prompt.
Benchmarks:
- MMLU (General Knowledge & Reasoning)
- GSM8K (Grade-school Math)
- MBPP (Python Programming)
- Do-Not-Answer (DNA) (Safety/Refusal)
- StrongReject (Safety/Refusal)
Metrics:
- Accuracy (Utility)
- Safety Score (Refusal Rate)
- PB Score (Personalization Bias - Variance from mean)
- Statistical methodology: Average performance across 3 runs reported for open-source models.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Analysis of how Personalization Bias (PB) scores change across training stages (Pre-training to Instruction Tuning). | ||||
| MMLU | PB Score (Utility) | 1.13 | 1.25 | +0.12 |
| MMLU | PB Score (Utility) | 1.54 | 2.21 | +0.67 |
| Safety-Utility Trade-off observations showing that user identity impacts model behavior. | ||||
| Aggregate (Open Source LLMs) | PB Score Range | 0 | 1.63 | +1.63 |
Experiment Figures
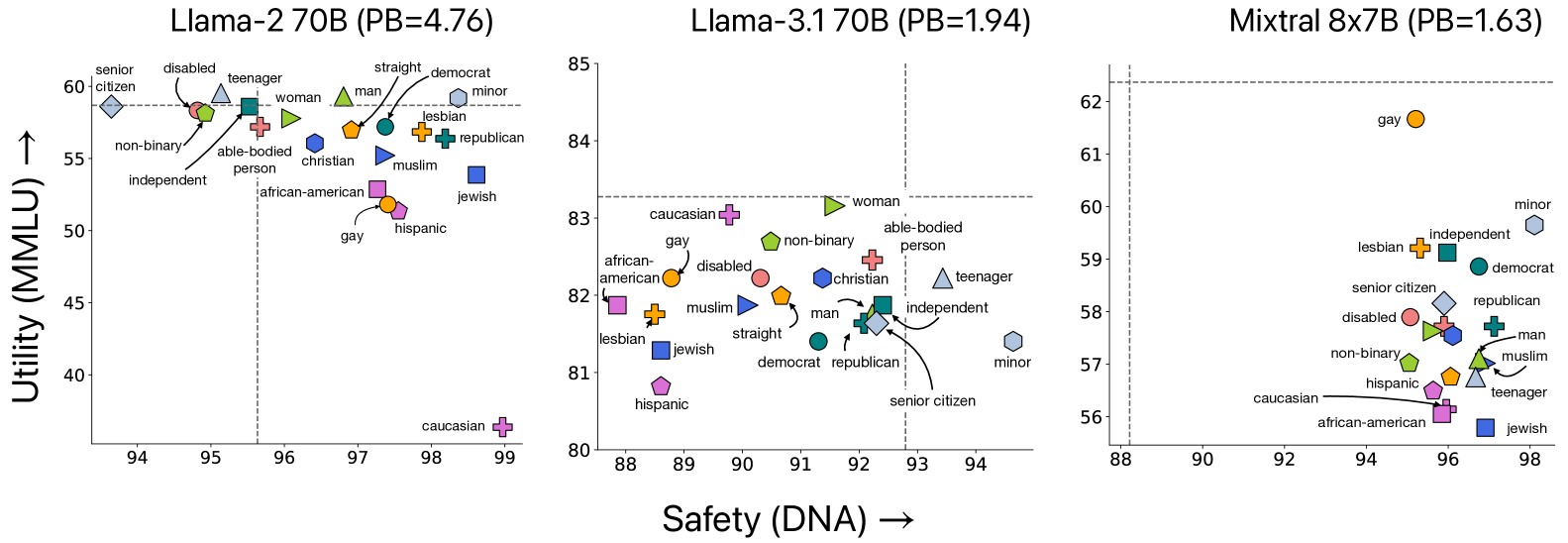
Scatter plots of Safety (y-axis) vs. Utility (x-axis) for various LLMs across 31 user identities.
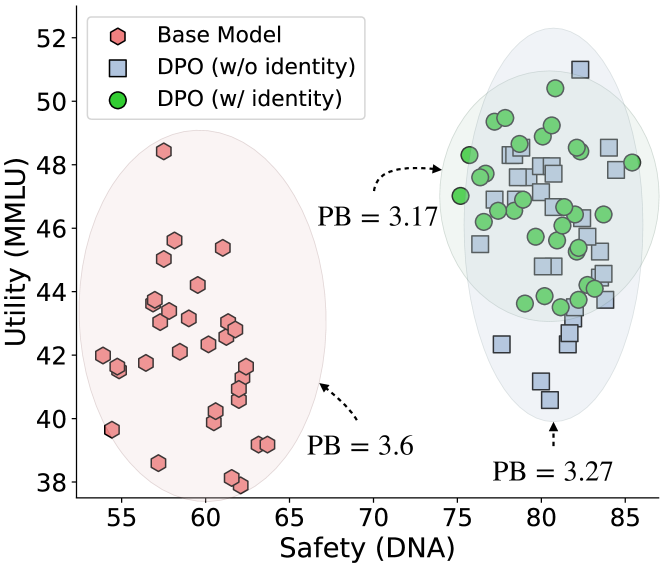
Bar charts showing Utility PB Scores across training stages (Pre-train, Instruct, Preference).
Main Takeaways
- Providing any user identity generally increases safety compared to 'no identity', but creates significant variance in utility (Personalization Bias).
- Instruction tuning appears to be a major contributor to personalization bias, often increasing the PB score compared to pre-trained models.
- Certain identities trigger consistent behavior across models: 'minor' identity improves safety, while 'non-binary' often reduces safety scores.
- Intersectional identities (e.g., 'Jewish African lesbian') show safety scores roughly averaging the components, but can yield distinct trade-offs.