📝 Paper Summary
Robotic Task Planning
Agentic Personalization
Household Robotics
LLM-Personalize aligns robotic agents to household-specific preferences by combining imitation learning for initial capability with reinforced self-training for iterative preference learning.
Core Problem
General-purpose LLM planners lack alignment with specific household preferences (personalization), often failing to place objects where specific users want them despite understanding physical affordances.
Why it matters:
- General LLM knowledge reflects common sense, which may conflict with unique individual habits (e.g., placing a mug in a cabinet vs. on a table)
- Existing grounding methods focus on physical feasibility (affordances) or static scene graphs, neglecting the personalization gap in household robotics
- Scalability to long-horizon, partially observable tasks remains challenging for standard LLM prompting methods
Concrete Example:
One household may prefer a coffee mug on the dining table, while another prefers it in a kitchen cabinet. A standard LLM might default to a generic location, failing to satisfy the specific user's 'correct' placement criteria.
Key Novelty
Imitation-Bootstrapped Reinforced Self-Training for Robotics
- Bootstraps the planner using Imitation Learning on a demonstrator to ensure it can parse complex contexts and generate executable plans
- Refines the planner via Reinforced Self-Training (ReST), where the model iteratively generates plans, filters them based on user preference rewards, and fine-tunes on the successful examples
- Uses a dynamic scene graph within the prompt to handle partial observability, updating the agent's belief state as it explores the house
Architecture
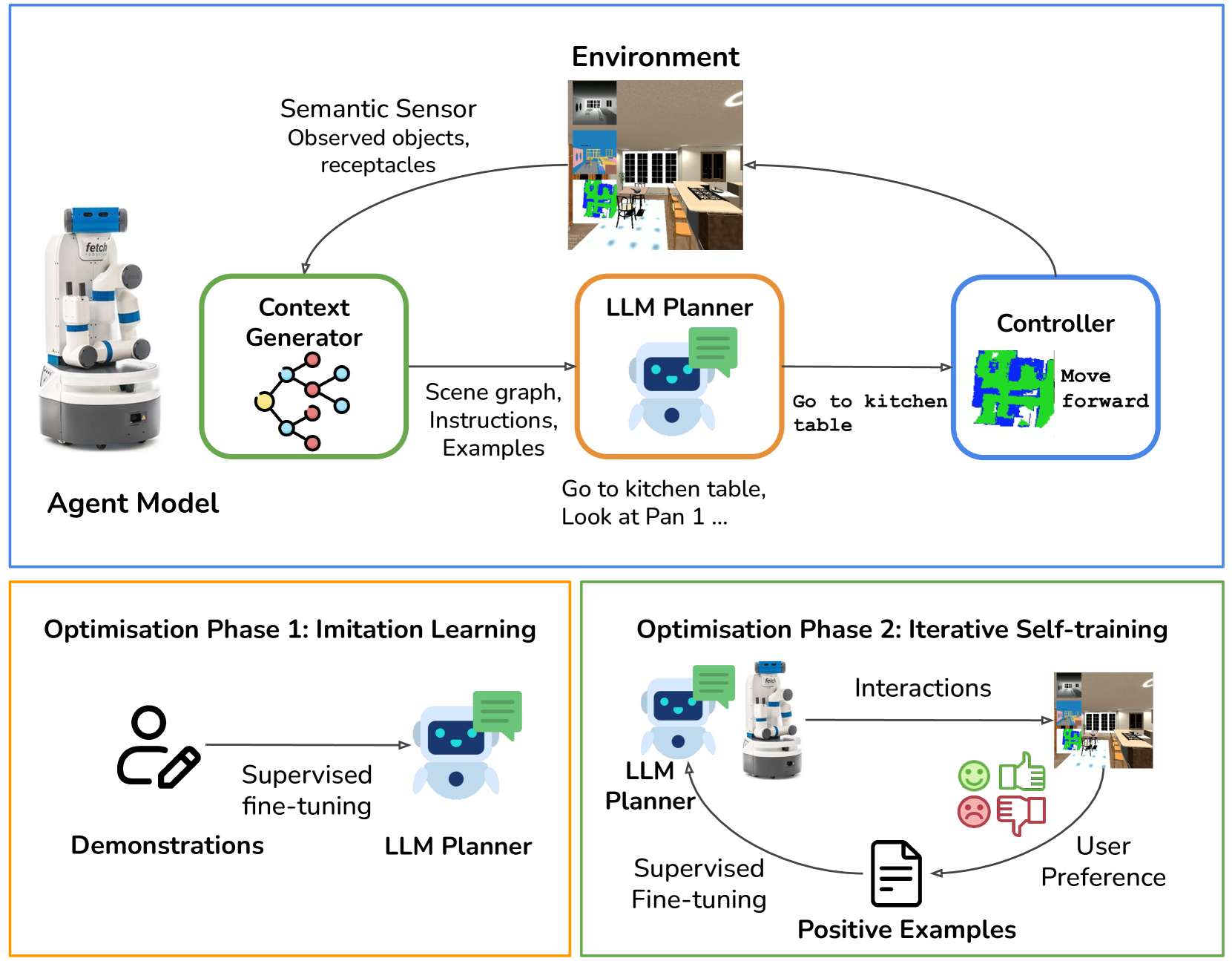
The overall framework of LLM-Personalize in the Housekeep environment.
Evaluation Highlights
- Achieves >30% increase in success rate over existing LLM planners (Song et al., Ahn et al., Rana et al.) on the Housekeep benchmark
- Demonstrates significantly improved alignment with human preferences in long-horizon object rearrangement tasks
Breakthrough Assessment
7/10
Addresses a critical gap (personalization) in embodied AI with a sound methodology (ReST), showing strong reported gains, though the core technique is an application of existing RL/LLM methods to a new domain.