📝 Paper Summary
Heterogeneous Federated Learning
Model Personalization
pFedHR enables personalized federated learning for clients with different model architectures by disassembling client models into layers, regrouping them by function, and stitching them into new candidate models for matching.
Core Problem
Standard Federated Learning (FL) requires identical model architectures across clients, preventing participation from heterogeneous clients (e.g., companies with proprietary models). Existing solutions rely on consensus (eroding personalization) or predefined distillation structures (limiting flexibility).
Why it matters:
- Real-world FL participants often possess distinct, pre-existing models and cannot simply replace them with a global architecture
- Current methods using public data for alignment suffer severe performance drops when public data distribution differs from client data
- Consensus-based methods (averaging logits/representations) compromise privacy and dilute the unique characteristics necessary for personalization
Concrete Example:
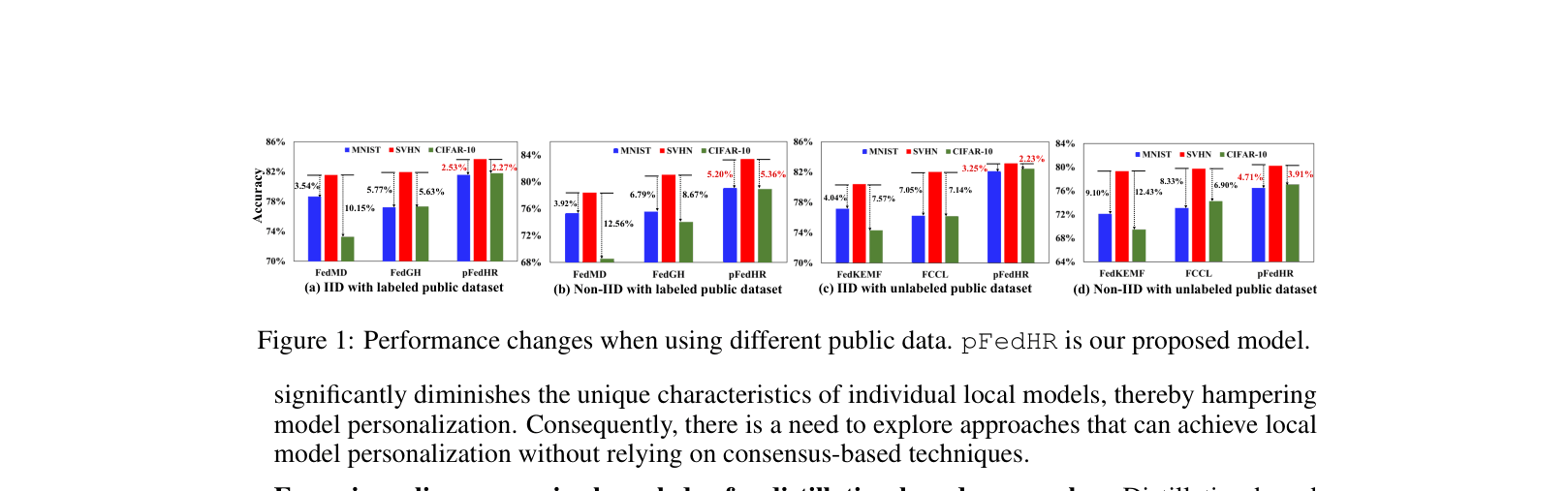
If Client A has a shallow CNN and Client B has a deep ResNet, standard FedAvg cannot aggregate their weights. Existing methods might force them to distill knowledge into a shared 'student' model, but if the public dataset used for distillation differs from their private data (e.g., SVHN vs. CIFAR), performance collapses (e.g., 3.5% to 12% drops in baselines).
Key Novelty
Heterogeneous Model Reassembly (pFedHR)
- Treats personalization as a matching problem: instead of averaging weights, the server decomposes uploaded models into layers and reassembles them into many new candidate architectures
- Uses 'function-driven layer grouping' to cluster layers from different clients based on their behavior on public data, ensuring semantically similar layers are grouped regardless of dimensions
- Selects the single best-matching reassembled candidate for each client based on output similarity, then stitches the layers together using lightweight linear connectors
Architecture
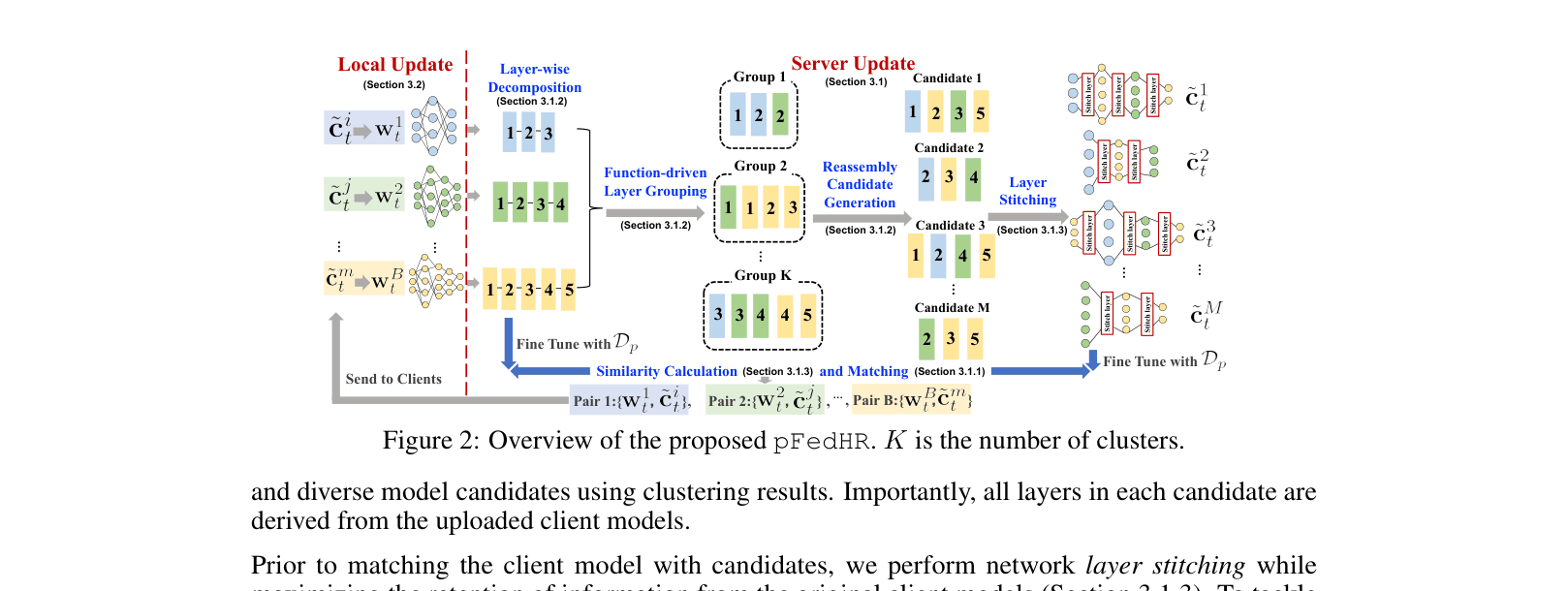
Overview of the pFedHR framework, detailing the interaction between Client Update and Server Update phases.
Evaluation Highlights
- Outperforms FedGH by +1.74% (83.68% vs 81.94%) on SVHN (IID setting) using labeled public data
- Achieves 78.98% accuracy on SVHN with 100 clients (large-scale setting), surpassing FCCL (75.03%) and FedKEAF (76.27%)
- Maintains robustness when public data differs from client data (e.g., training on SVHN using CIFAR-10 public data), showing significantly lower performance drops compared to baselines
Breakthrough Assessment
8/10
Novel application of model reassembly/stitching to the FL heterogeneity problem. Successfully moves away from consensus/distillation paradigms, addressing a critical practicality gap in FL.