📝 Paper Summary
Personalized Image Generation
Compositional Personalization
Style Transfer
FreeTuner achieves training-free personalization by decoupling generation into a structure-preserving content stage using attention injection and a texture-aligning style stage using feature guidance.
Core Problem
Existing personalization methods typically focus on either subject or style alone, and composing them usually requires training separate encoders or fine-tuning (e.g., LoRA), which leads to concept entanglement and high computational costs.
Why it matters:
- Current tuning-based methods (like DreamBooth) require multiple images and per-concept training, which is computationally expensive and slow.
- Adapter-based methods struggle to disentangle style from subject without large-scale paired datasets, which are difficult to collect due to the subjective nature of 'style'.
- Artists and creators need 'compositional personalization' (specific subject in a specific style) to spark creativity, but existing unified training paradigms confuse the model, degrading either subject identity or style fidelity.
Concrete Example:
If a user wants to generate a 'horse walking in Times Square' (subject) in a 'Van Gogh' style (style), current methods might lose the horse's structure (over-stylization) or fail to capture the brushwork (entanglement), and would require fine-tuning separate LoRAs for the horse and the style first.
Key Novelty
Training-free Content-Style Decoupling Strategy
- Splits the denoising process into two distinct phases: an early 'Content Generation Stage' that locks in subject structure and a later 'Style Generation Stage' that applies aesthetic textures.
- Injects intermediate features (attention maps and latent codes) from a reference reconstruction process directly into the generation process to copy subject layout without training.
- Uses standard pre-trained feature extractors (VGG) to guide the diffusion noise predictions toward the target style in the later steps, similar to neural style transfer but applied to diffusion latents.
Architecture
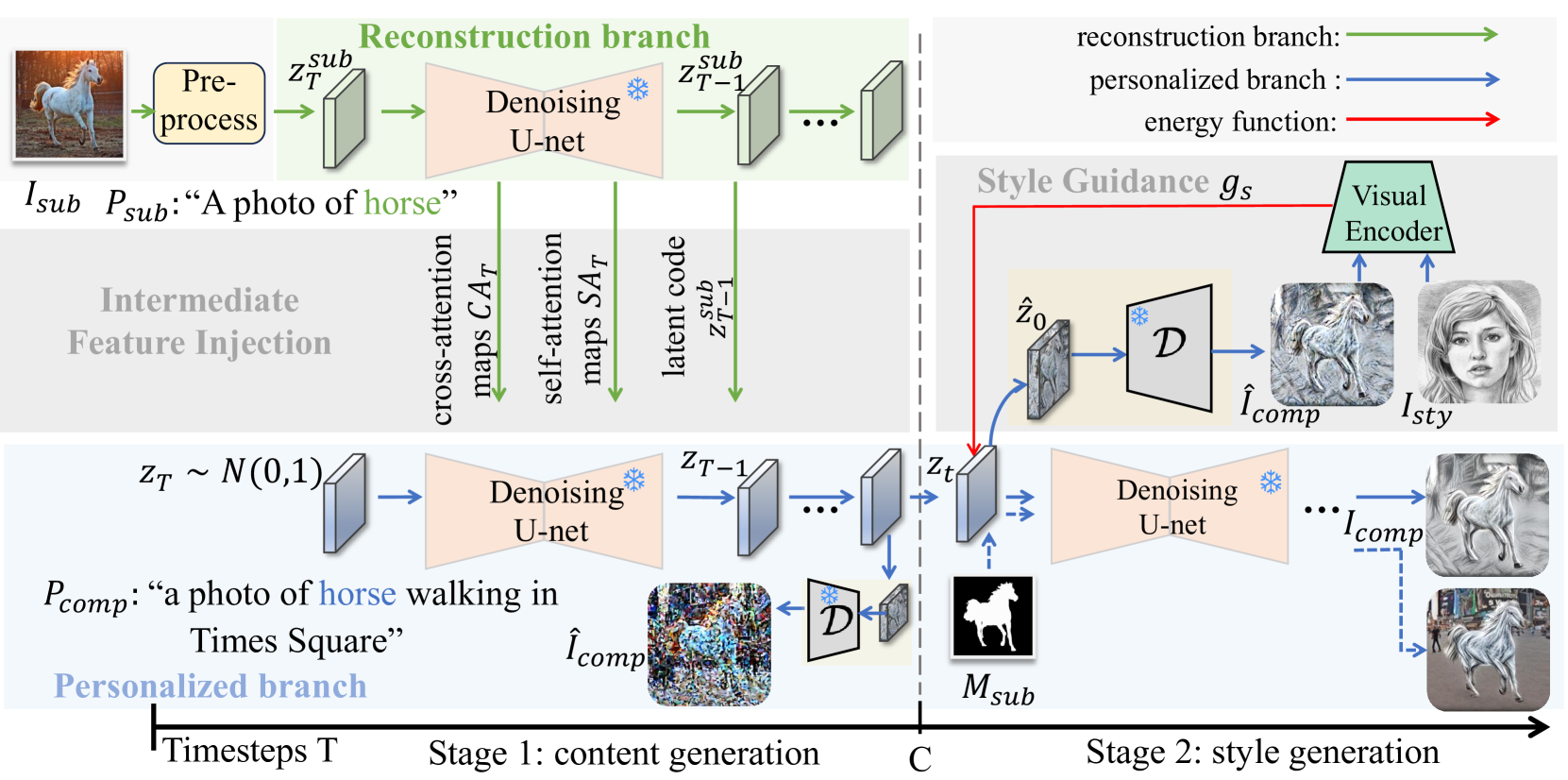
The FreeTuner pipeline illustrating the two-stage generation process: Content Generation and Style Generation.
Breakthrough Assessment
8/10
The paper proposes the first training-free solution for subject-style compositional personalization, significantly reducing the barrier to entry (1 image, no fine-tuning) compared to LoRA/DreamBooth pipelines.

