📝 Paper Summary
Medical Dialogue
Conversational Personalization
BianQue enhances health LLMs' ability to ask proactive clarifying questions by fine-tuning on a large-scale dataset where ChatGPT polishes the consultation history to balance questions and suggestions.
Core Problem
Current health LLMs provide generic suggestions based on single-turn user inputs and lack the ability to conduct 'Chain of Questioning' (CoQ) to fully understand a patient's condition before advising.
Why it matters:
- Real-world doctors rely on iterative inquiries to provide personalized and effective advice, a capability missing in standard LLMs
- Existing datasets and models assume users clearly describe problems in one turn, ignoring the diagnostic process
- Lack of questioning leads to inadequate personalization, requiring users to self-filter generic advice
Concrete Example:
In a pediatric consultation, a doctor might ask 9 rounds of questions (e.g., about a baby's symptoms) before diagnosing. Current LLMs usually skip this inquiry phase and immediately provide broad, non-targeted advice.
Key Novelty
BianQueCorpus and BianQue Model
- Constructs a massive dataset (BianQueCorpus) by using ChatGPT to 'polish' (rewrite/expand) doctor suggestions from raw web data while retaining the original proactive questions
- Balances the training data distribution to contain roughly equal parts questioning (46.2%) and suggestions (53.8%) to prevent the model from only learning to answer
- Fine-tunes ChatGLM-6B specifically to learn the 'Chain of Questioning' capability alongside providing medical advice
Architecture
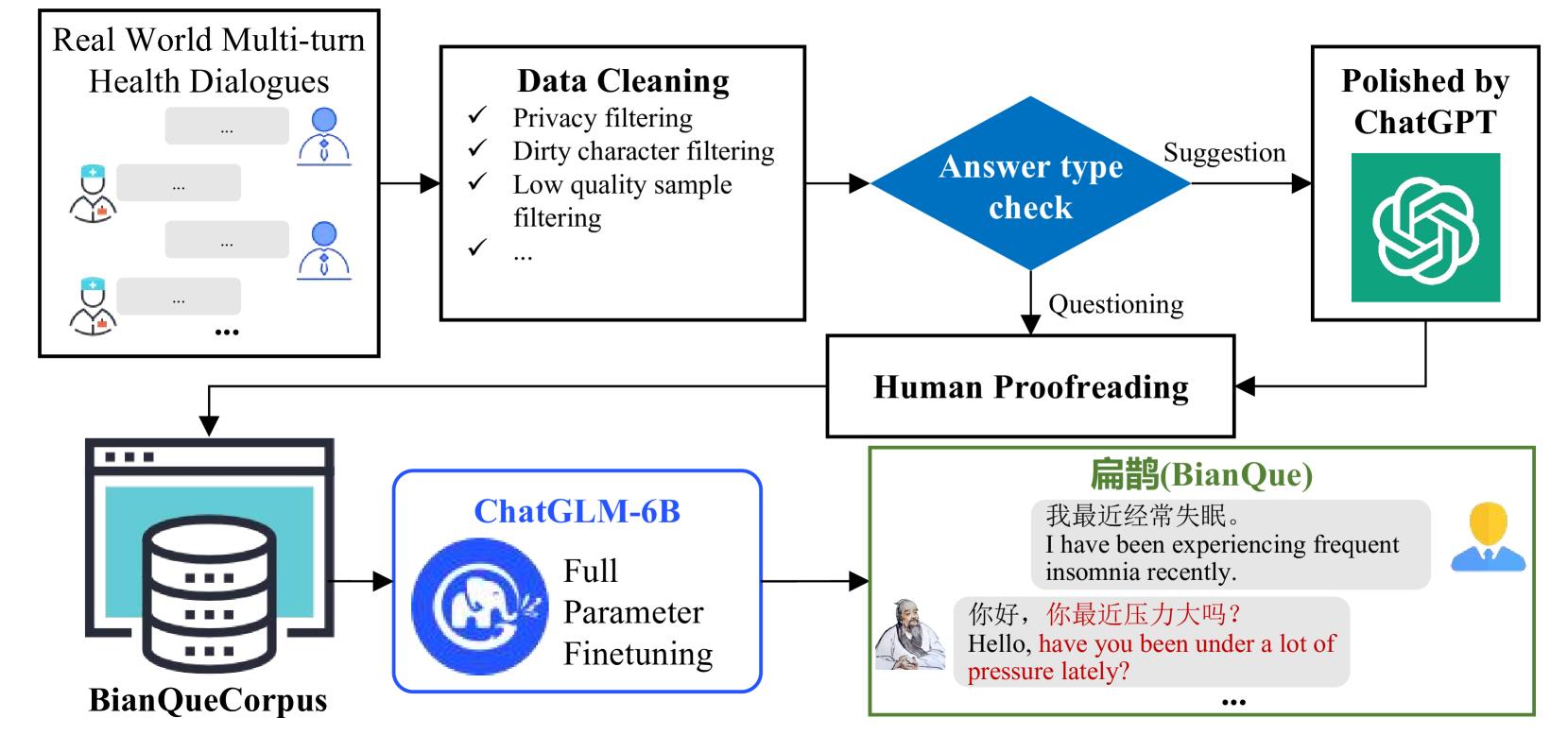
The construction process of the BianQueCorpus dataset.
Evaluation Highlights
- BianQueCorpus contains 2,437,190 samples with a balanced distribution of questions (46.2%) and suggestions (53.8%)
- Qualitative results indicate BianQue outperforms ChatGLM-6B, ChatGPT, and DoctorGLM on multi-turn conversation datasets (MedDialog-CN, IMCS-V2, etc.)
- Data cleaning improved the 'excellent rate' of the corpus from 82% to 93% before training
Breakthrough Assessment
7/10
Addresses a critical gap in medical LLMs (lack of inquiry). The methodology of using ChatGPT to polish dataset suggestions to balance the distribution is practical and effective.

