📝 Paper Summary
Personalized Dialogue Generation
Benchmark Datasets
Evaluation Methodologies
This survey systematizes the field of personalized dialogue generation by analyzing 22 datasets and classifying 17 recent methodologies into five core problem domains, ranging from consistency to data scarcity.
Core Problem
Personalized dialogue generation lacks a unified definition and standardized benchmarks; current research is fragmented across varying goals (agent persona vs. user modeling) and relies on datasets with significant domain and language biases.
Why it matters:
- Personalization is critical for user engagement, yet current datasets are often limited in size, quality, and diversity
- Methodologies vary widely in how they define 'persona' (explicit text vs. implicit history), making cross-comparison difficult without a structured taxonomy
- Language bias is severe; most resources focus on English/Chinese, leaving other languages with insufficient training data for personalized agents
Concrete Example:
While PersonaChat is the standard benchmark, it only contains English dialogues. Its multilingual variant, XPersona, is severely limited, containing only 280 dialogues for Italian, making it insufficient for robust training compared to the 10.9K dialogues in the English version.
Key Novelty
Comprehensive Taxonomy of Personalized Dialogue
- Classifies 17 seminal works (2021-2023) into five distinct problem types: Consistency/Coherence, Persona-Context Balancing, Relevant Persona Selection, Unknown Persona Modeling, and Data Scarcity
- Categorizes 22 datasets based on persona representation (descriptive sentences, key-value attributes, or user ID/history) and features (multi-session, multi-modal, grounding)
Architecture
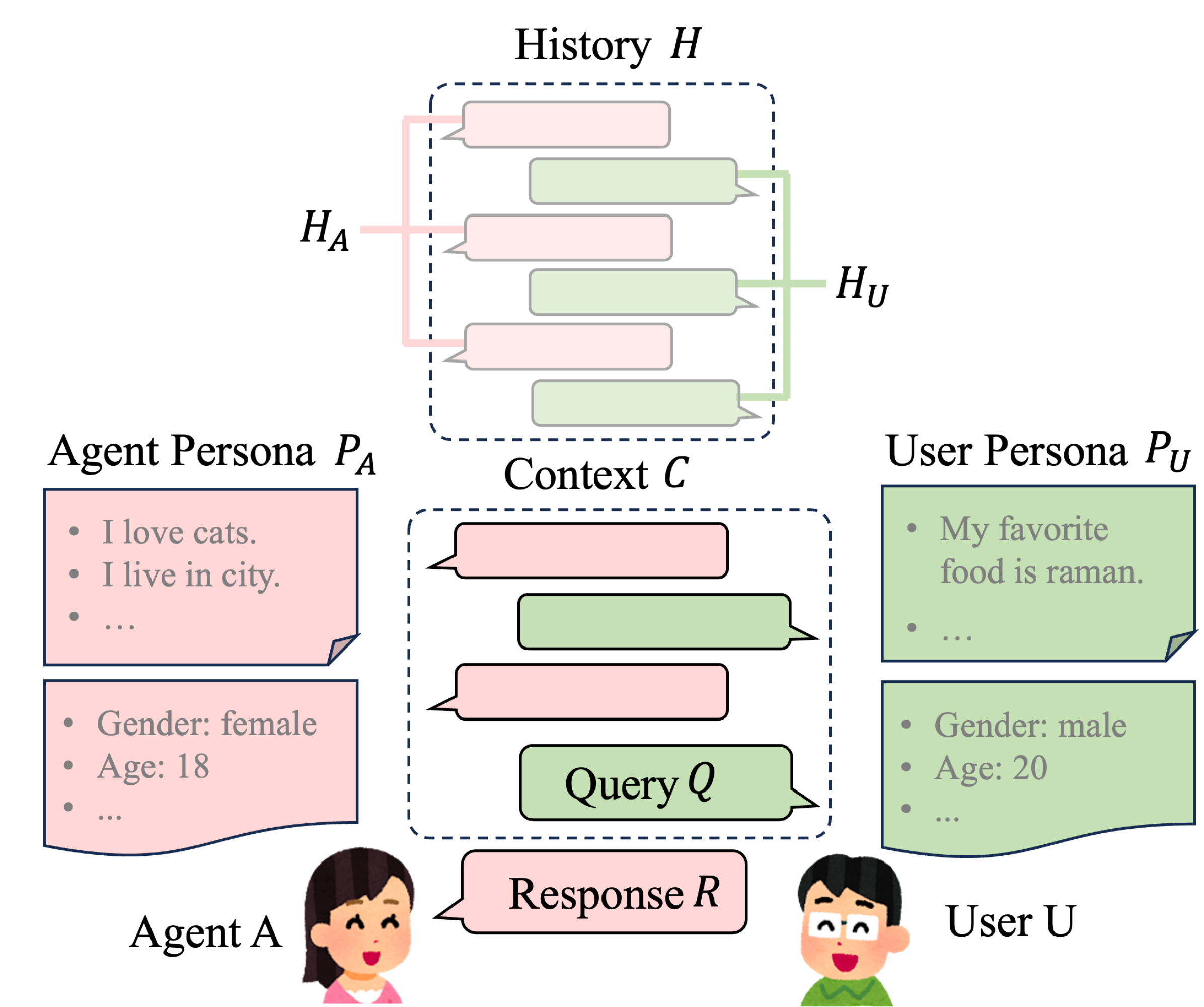
Conceptual taxonomy of the three personalization scenarios in dialogue generation research
Evaluation Highlights
- Identified 22 distinct datasets, establishing PersonaChat (10.9K dialogues) as the dominant benchmark used in 9 of 18 reviewed works
- Highlighted severe data scarcity in multilingual resources, specifically noting XPersona contains only 280 Italian dialogues compared to thousands in English
- Analyzed 17 top-conference papers to identify that recent trends represent persona in three distinct ways: description (most common), key-value attributes, or raw user history
Breakthrough Assessment
7/10
A solid systematic review that organizes a fragmented field. While it doesn't propose a new model, its taxonomy of 5 problem types and cataloging of 22 datasets provides a necessary roadmap for future research.