📝 Paper Summary
LLM-based recommendation
Agentic AI (Planning)
ItiNera integrates Large Language Models for intent understanding with mathematical spatial optimization to generate personalized, feasible urban travel itineraries without hallucinations or inefficient routing.
Core Problem
Existing itinerary planning is either purely optimization-based (lacking personalization/flexibility) or purely LLM-based (prone to POI hallucinations and spatially incoherent routing).
Why it matters:
- Pure LLMs (like GPT-4) cannot reference specific POI lists reliably, leading to non-existent destinations
- LLMs lack spatial reasoning capabilities, often generating 'zig-zag' routes that waste travel time
- Traditional operations research methods (like TSP solvers) cannot understand nuanced natural language preferences (e.g., 'a quiet cafe with a retro vibe')
Concrete Example:
A user asks for a 'citywalk including art spots and coffee.' An LLM might suggest a museum that is closed or route the user back and forth across the city efficiently. ItiNera retrieves valid open spots and orders them using spatial clustering.
Key Novelty
LLM-Solver-LLM Sandwich Architecture
- Decomposes the problem: Uses LLMs to understand *what* to visit (intent decomposition) and *how* to describe it (final generation), but delegates *where* and *when* to a mathematical solver
- Introduces a 'Hierarchical TSP' module in the loop: Clusters retrieved points of interest spatially and solves the Traveling Salesman Problem to ensure the route is physically logical before the LLM writes the final narrative
Architecture
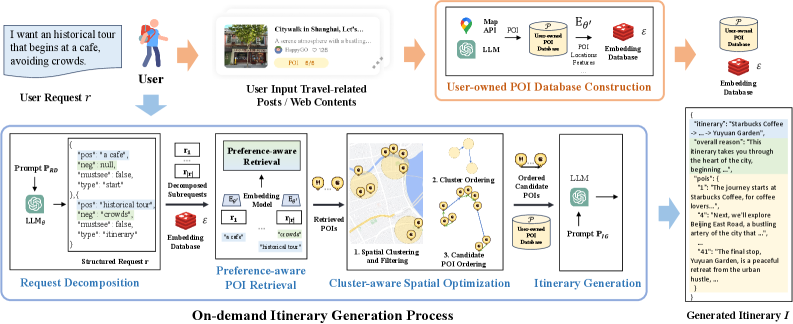
The complete inference pipeline of ItiNera.
Evaluation Highlights
- Achieves ~30% improvement in rule-based metrics (Recall, Spatial Margin) over best baselines (including GPT-4 CoT)
- Maintains spatial coherence by generating itineraries only ~100 meters longer per POI than the theoretical shortest path (TSP)
- Outperforms GPT-4 CoT on 'Match' (alignment with user request) in human-aligned LLM evaluations
Breakthrough Assessment
7/10
Strong engineering integration of symbolic AI (optimization) and connectionist AI (LLMs) for a practical application. Solves the specific 'spatial hallucination' problem of LLMs effectively.