📝 Paper Summary
Multi-agent travel planning
Personalized recommendation via Agents
Memory-augmented planning
TravelAgent is a modular LLM-based system that integrates tool use, memory, and personalized recommendation to generate rational, comprehensive, and budget-aware travel itineraries.
Core Problem
Existing LLM-based travel planners often fail to handle dynamic real-world constraints (e.g., closed attractions, budget limits) or lack personalization, resulting in irrational or generic itineraries.
Why it matters:
- Standard LLMs hallucinate non-existent routes or ignore opening hours, leading to impossible travel plans.
- Static rule-based systems lack the flexibility to adapt to user-specific preferences (soft constraints) like dietary needs or pacing.
- Without memory of past interactions, agents cannot evolve to understand a user's long-term preferences across different trips.
Concrete Example:
A user might request a trip with a strict budget. A standard LLM might suggest luxury dining that exceeds the daily limit or schedule a museum visit on a day it is closed. TravelAgent uses a budget planner to allocate funds first and checks opening hours via tools to ensure feasibility.
Key Novelty
Constraint-Aware Modular Agent System
- Decomposes travel planning into distinct modules (Tool, Recommendation, Planning, Memory) rather than a single end-to-end prompt.
- Introduces a specific 'Budget Planner' that strategically distributes funds across categories (e.g., dining vs. accommodation) before generating the itinerary.
- Uses a spatiotemporal scoring algorithm to select the next attraction based on distance, remaining time, and opening hours, ensuring logistical rationality.
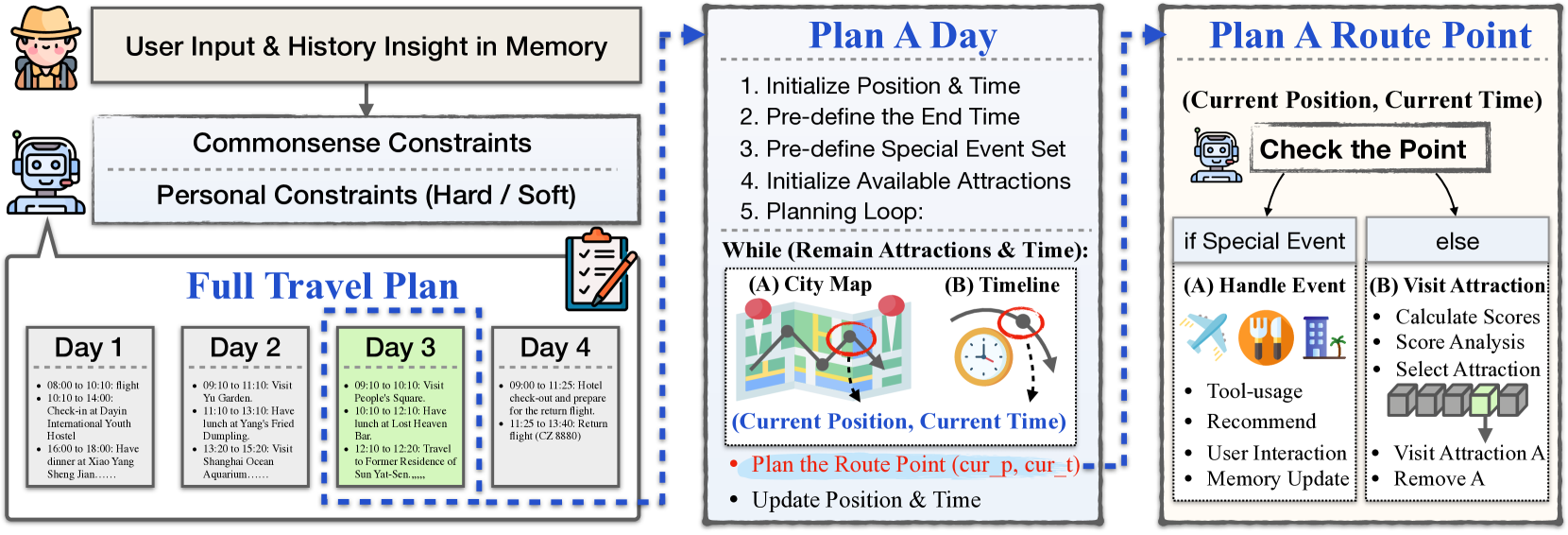
Architecture

The overall architecture of TravelAgent showing the interaction between the four main modules.
Evaluation Highlights
- Outperforms GPT-4+ Agent baseline in 'Rationality' (90% vs 50% pass rate) in human evaluation case studies.
- Achieves lower error rates (RMSE) in attraction recommendation compared to baseline LLM-based recommendation methods (KoLA, P5, LLM-Rec) in simulation experiments.
- Demonstrates high 'Comprehensiveness' score (4.8/5.0) in human evaluations, significantly higher than the baseline (3.1/5.0).
Breakthrough Assessment
7/10
Strong engineering system integrating memory, tools, and constraints for a specific vertical (travel). While the components (RAG, memory) are known, the specific application to budget/spatial constraints is well-executed.