📝 Paper Summary
Subjective text perception
User-specific fine-tuning
The paper demonstrates that fine-tuning LLMs with simple user identifiers significantly outperforms zero-shot and few-shot in-context learning for subjective tasks like emotion recognition and hate speech detection.
Core Problem
Standard LLMs are trained to be universal and objective, often failing to capture the highly subjective nature of tasks where 'correct' labels depend on individual user biases and preferences.
Why it matters:
- Subjective tasks (emotion, hate speech, humor) rely heavily on individual interpretation, meaning a 'one-size-fits-all' model often misclassifies valid personal perspectives
- Current zero-shot methods do not permanently update model weights to reflect user history, leading to inconsistent or generic responses that ignore individual context
- Personalization is critical for user satisfaction in recommendation systems and chatbots, yet LLM personalization for subjective text perception remains under-explored
Concrete Example:
In hate speech detection, one user might find a comment 'antagonistic' while another finds it 'healthy'. A standard LLM predicts a single label based on general consensus, ignoring the specific user's sensitivity or history, leading to a prediction that matches neither user's view.
Key Novelty
User-ID-Based Personalized Fine-Tuning (CLS-P / LM-P)
- Incorporates a unique User ID token directly into the prompt during fine-tuning, allowing the model to learn user-specific embeddings or biases alongside text features
- Compares two distinct architectures for personalization: adding a classification head (CLS-P) versus treating the problem as text generation (LM-P), identifying which works best for different label complexities
Architecture
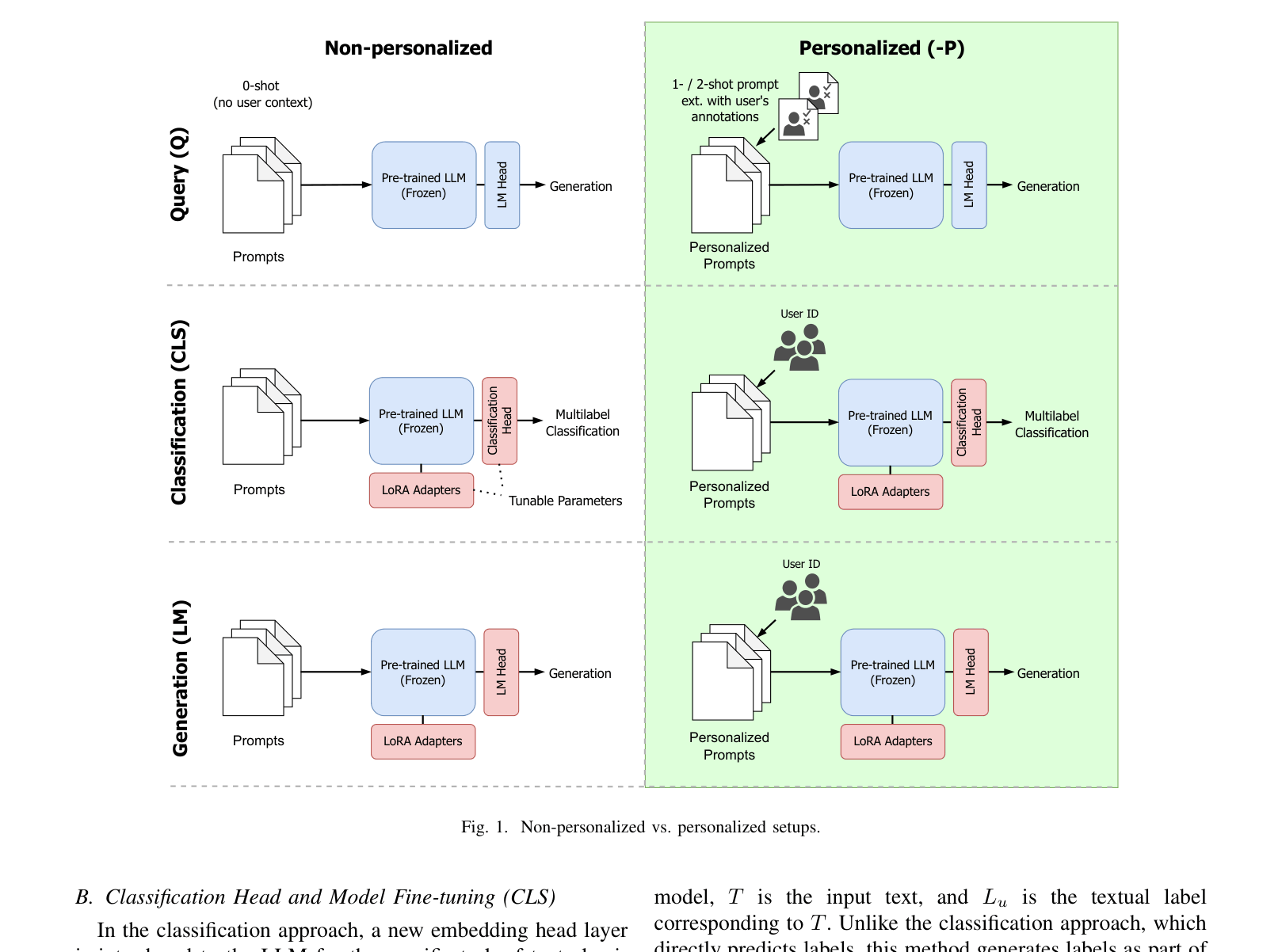
Comparison of three workflows: Non-personalized Query (Zero-shot), Personalized Classification (CLS-P), and Personalized Generation (LM-P).
Evaluation Highlights
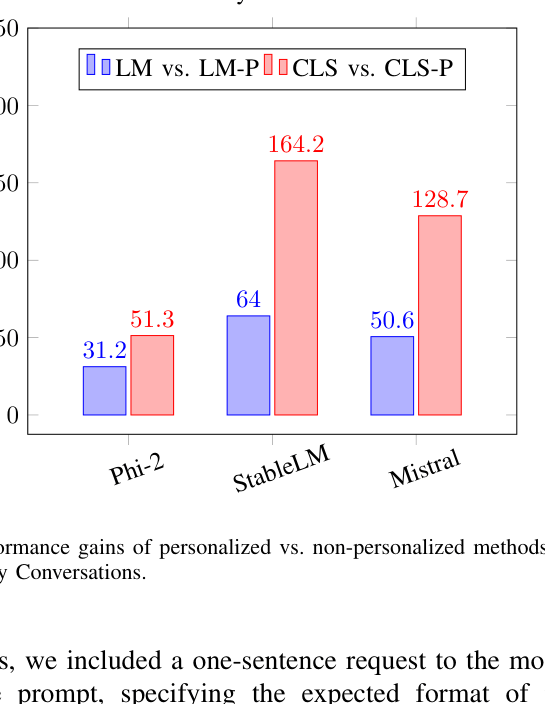
- +164.2% performance gain (relative) on Unhealthy Conversations using Mistral 7B with personalized fine-tuning (CLS-P) compared to non-personalized baseline
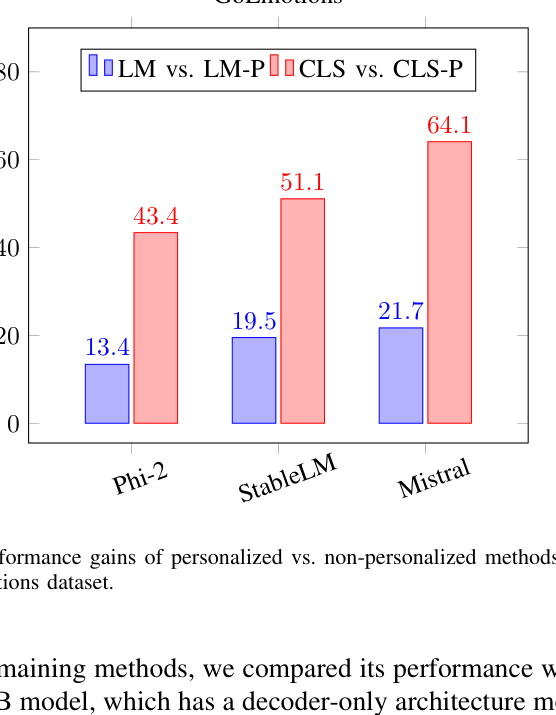
- +64.1% performance gain on GoEmotions using Mistral 7B with personalized fine-tuning (CLS-P) compared to non-personalized baseline
- Fine-tuned personalization (CLS-P) consistently outperforms few-shot in-context learning (Q-2S), even when using powerful models like GPT-4
Breakthrough Assessment
7/10
Provides strong empirical evidence that simple ID-based fine-tuning is highly effective for subjective tasks, significantly beating strong few-shot baselines. The method is simple but the gains are massive.