📝 Paper Summary
Personalized Federated Learning (pFL)
Conditional Computing in FL
FedCP uses a lightweight Conditional Policy Network to dynamically separate global and personalized information within feature vectors for each sample, processing them through distinct global and personalized heads.
Core Problem
Existing pFL methods treat model parameters as the sole unit of personalization, neglecting that the underlying data features themselves contain a mix of global and personalized information.
Why it matters:
- Treating all features uniformly fails to capture fine-grained distinctions in non-IID data, leading to suboptimal performance on local clients.
- Simply fine-tuning a global model or regularizing local training does not explicitly disentangle shared knowledge from client-specific nuances at the data level.
Concrete Example:
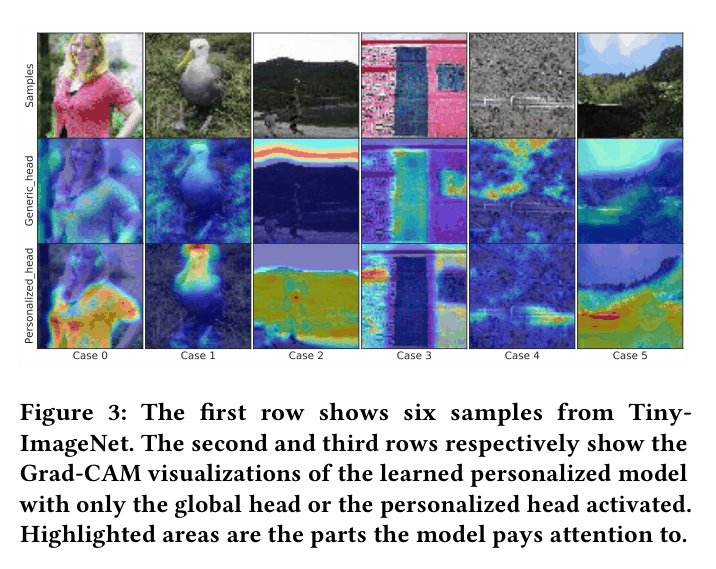
In an image dataset, a 'dog' (global concept) might appear on a 'pink rug' (rare/personalized context). Traditional pFL methods process the entire image feature through one model, whereas FedCP separates the 'dog' features for a global head and 'pink rug' features for a personalized head.
Key Novelty
Sample-Specific Feature Separation via Conditional Policy
- Introduces a Conditional Policy Network (CPN) that acts like a dynamic router, generating a soft mask for every input sample to split its features into global and personalized components.
- Uses a dual-head architecture where 'global' features are processed by a frozen global head (to preserve shared knowledge) and 'personalized' features by a trainable local head.
- Generates the routing policy based on both the sample itself and a client-specific embedding derived from the local personalized head.
Architecture
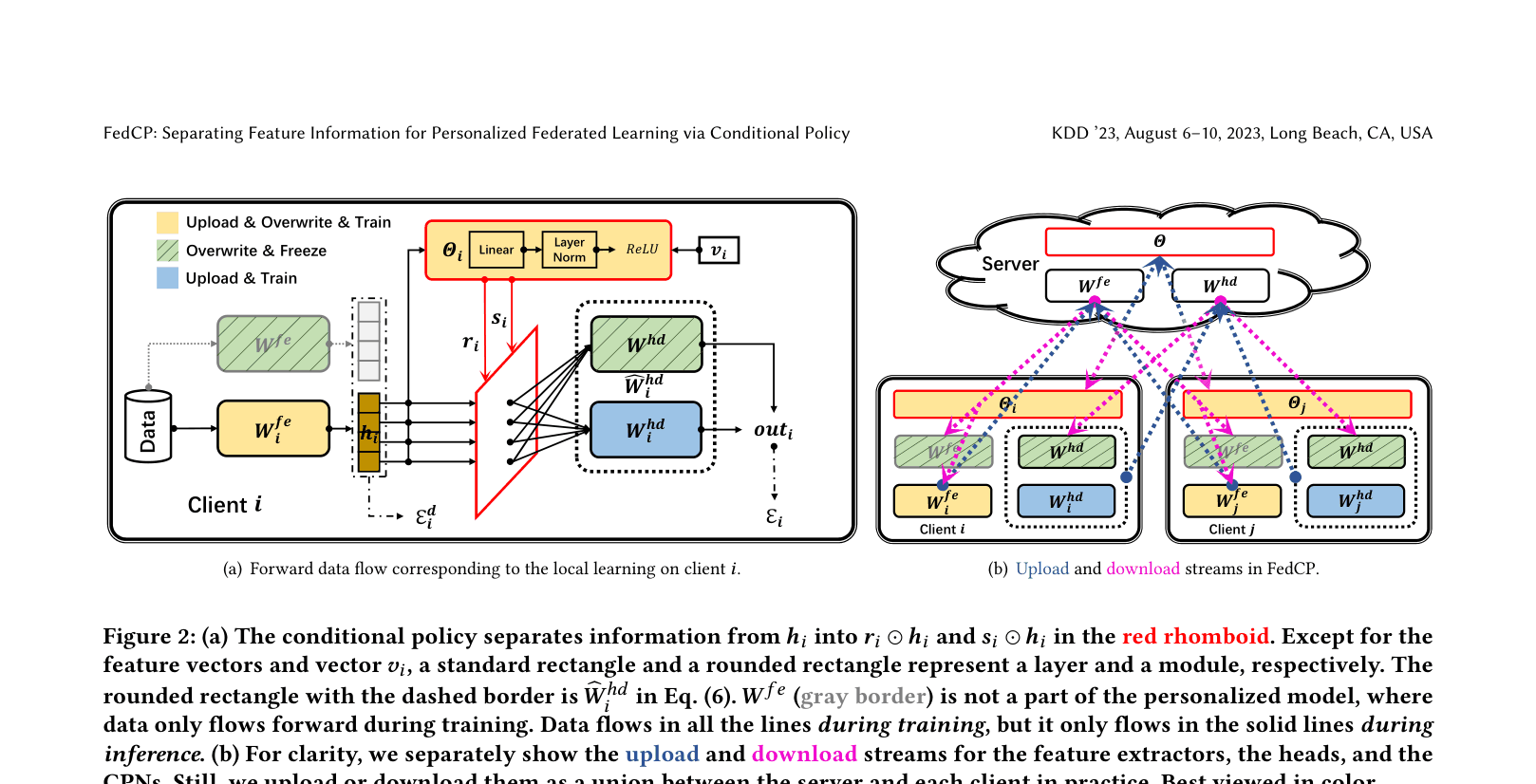
The complete forward pass and data flow of FedCP on a client.
Evaluation Highlights
- Outperforms state-of-the-art method Ditto by +6.69% accuracy on Cifar100 in practical non-IID settings.
- Achieves superior stability in scenarios where clients accidentally drop out, maintaining ~54% accuracy on Cifar100 while baselines like pFedMe drop significantly.
- Incurs only ~4.67% additional parameters per client compared to ResNet-18, making it communication-efficient.
Breakthrough Assessment
8/10
Significantly shifts the pFL focus from model-level to feature-level personalization. The explicit separation mechanism yields substantial gains on hard tasks (Cifar100) and robustness to client dropout.