📝 Paper Summary
Personalized Dialogue Systems
Dynamic User Modeling
RLPA trains language models to dynamically infer and adapt to user profiles during dialogue by optimizing a dual-level reward signal (profile accuracy and response alignment) via interaction with a simulated user.
Core Problem
Existing personalized alignment methods (like Prompting, SFT, DPO) rely on static datasets or templates, failing to adapt in 'cold-start' scenarios where user preferences must be inferred dynamically from interaction.
Why it matters:
- Static methods cannot handle the evolving nature of long-term human-AI interaction where users reveal preferences gradually.
- Offline optimization (SFT/DPO) requires large labeled datasets of user profiles, which are unavailable for new users (cold-start problem).
- Prompt-based personalization is superficial and constrained by context window limits, often failing to maintain coherence over long conversations.
Concrete Example:
In a cold-start scenario, a new user might implicitly reveal a dietary restriction halfway through a chat. A static SFT model, trained on fixed profile-response pairs, might miss this subtle cue because it lacks an explicit mechanism to update its internal user state, leading to a recommendation that violates the user's needs.
Key Novelty
Reinforcement Learning for Personalized Alignment (RLPA)
- Formulates personalization as a multi-turn Markov Decision Process (MDP) where the model explicitly generates and updates a structured user profile estimate at every turn.
- Trains the model using a Simulated User (GPT-4o-mini) that holds a hidden profile and reveals it gradually, removing the need for static human-labeled datasets.
- optimizes a dual-reward objective: a 'Profile Reward' for accurately guessing the hidden user attributes and a 'Response Reward' for generating replies that match that inferred profile.
Architecture
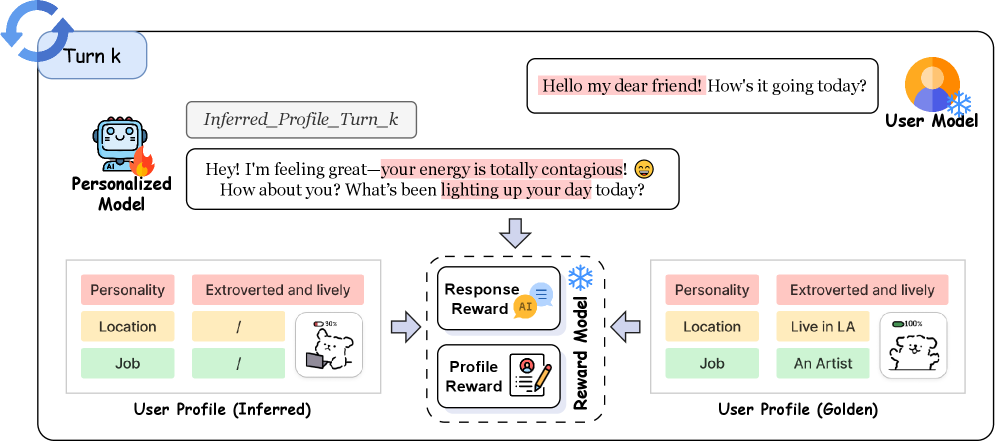
The RLPA training framework, illustrating the interaction loop between the Agent and the Simulated User.
Evaluation Highlights
- Achieves 66.86 average alignment score on ALOE Vanilla benchmark, outperforming Supervised Fine-Tuning (SFT) by +29.06 points.
- Surpasses GPT-4o on the Extended ALOE benchmark (unseen attribute types) with a score of 67.12 vs 66.52, demonstrating superior generalization.
- Maintains stable performance over 10 dialogue turns while baselines like SFT and DPO degrade significantly after turn 5 (visualized in Figure 3).
Breakthrough Assessment
8/10
Significant shift from static to dynamic personalization using RL and simulated users. The performance gains over strong baselines (including GPT-4o) in generalization settings are impressive.
