📝 Paper Summary
Conversational personalization
Multi-turn Reinforcement Learning
CURIO enhances conversational personalization by incorporating a curiosity-based intrinsic reward into multi-turn RLHF, incentivizing agents to actively infer latent user traits during dialogue without requiring pre-existing profiles.
Core Problem
Standard RLHF optimizes for average user preferences or relies on extensive pre-collected user history, failing to adapt to new users with unknown traits during live interactions.
Why it matters:
- One-size-fits-all models fail in high-stakes domains like education and healthcare where individual traits (e.g., learning style, emotional state) determine success
- Real-world deployments often lack rich prior user data (cold start), rendering history-dependent personalization methods ineffective
- Current methods neglect long-term personalization by optimizing single-turn rewards, failing to strategically gather information over a conversation
Concrete Example:
A therapeutic chatbot trained on average user data might offer generic advice that fails to build rapport with a specific user, because it never learned to ask questions about the user's emotional history to tailor its approach.
Key Novelty
Curiosity-driven User-modeling Reward as an Intrinsic Objective (CURIO)
- Treat the user as a hidden environment state to be explored; the agent receives an intrinsic reward for actions that reduce uncertainty about the user's type
- Employ a separate 'User Model' that predicts user traits based on conversation history; the Policy is rewarded when it improves this User Model's prediction accuracy or reduces its entropy
- Integrate this intrinsic reward into multi-turn RLHF, balancing the exploitation of helpfulness rewards with the exploration of user attributes
Architecture
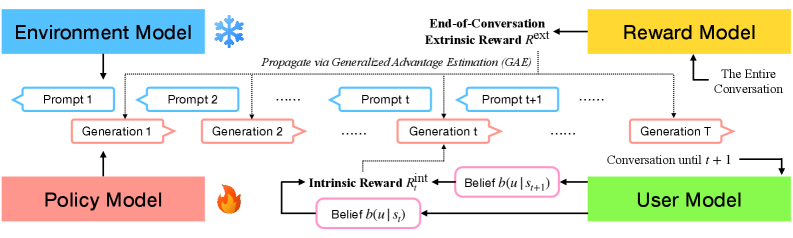
The training framework involving four distinct models: Policy, Environment, Reward, and User Model.
Breakthrough Assessment
7/10
Novel application of intrinsic motivation and POMDP theory to LLM personalization, addressing the cold-start problem without pre-computed profiles. Theoretical grounding in reward shaping is strong.