📝 Paper Summary
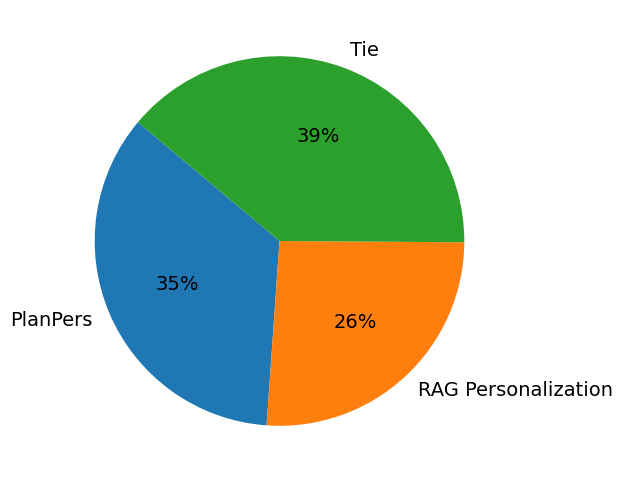
User-profile based personalization
RAG-based personalization
LaMP-QA is a benchmark for personalized long-form question answering that evaluates responses based on how well they address specific needs extracted from user-written question narratives, rather than just matching a single reference answer.
Core Problem
Existing personalization benchmarks focus on style mimicking (e.g., email writing) rather than information-seeking, while current evaluation methods rely on single accepted answers that may not reflect the full range of user preferences.
Why it matters:
- Personalization is critical for user satisfaction in search and generation, but the 'generation' aspect for information seeking is underexplored due to a lack of resources.
- Relying on a single 'accepted' answer for evaluation is flawed because users never see the full space of possible responses.
- Current benchmarks like LaMP and LongLaMP overlook information-seeking tasks where answers must be tailored to specific user intents and backgrounds.
Concrete Example:
A user asks a question on a forum about 'Arts & Entertainment'. A standard QA system gives a generic factual answer. However, the user's detailed narrative reveals they specifically care about 'budget-friendly options' and 'accessibility'. A non-personalized system misses these constraints, while a personalized system uses the user's history and narrative to address these specific needs.
Key Novelty
LaMP-QA Benchmark and Aspect-Based Evaluation
- Constructs a dataset from StackExchange where the 'user profile' is the user's history of past questions, and the 'current context' is the question plus a detailed narrative.
- Proposes a novel evaluation method where an LLM extracts specific 'rubric aspects' (requirements) from the user's question narrative and scores generated answers based on how well they satisfy these specific aspects.
Architecture
Conceptual flow of the benchmark creation and evaluation methodology.
Evaluation Highlights
- Incorporating personalized context (user profiles) leads to up to 39% performance improvement compared to non-personalized baselines.
- Using the target user's profile yields up to 62% better performance compared to using a mismatched (random other user's) profile, confirming the data is truly user-specific.
- Human annotators rated the quality of the automatically extracted evaluation aspects 4.9 out of 5, validating the proposed evaluation rubric generation.
Breakthrough Assessment
8/10
Significant contribution to personalized QA by moving beyond style transfer to information needs. The aspect-based evaluation using question narratives is a clever solution to the 'single reference answer' problem.