📝 Paper Summary
Personalized Text-to-Image Generation
Finetuning-free Customization
JeDi enables finetuning-free personalization by training a diffusion model on the joint distribution of multiple images sharing a subject, allowing new images to be generated via inpainting conditioned on reference images.
Core Problem
Existing personalization methods either require resource-intensive finetuning (slow, prone to overfitting) or use encoder-based finetuning-free approaches that suffer from information loss, failing to preserve identity details of uncommon subjects.
Why it matters:
- Users want to generate images of their specific possessions in new contexts without waiting for slow training processes
- Encoder-based methods often output generic versions of specific objects (e.g., a generic dog instead of a specific pet) due to compression loss
- Finetuning-based methods struggle with overfitting when only a few reference images are available
Concrete Example:
When given a reference image of a specific, unusual stuffed toy and asked to generate it 'on the beach', encoder-based methods like BLIP-Diffusion might generate a generic teddy bear, losing the unique texture and shape of the original toy.
Key Novelty
Joint-Image Diffusion (JeDi)
- Treats personalization as an inpainting task within a joint distribution: the model learns to generate a set of related images simultaneously rather than independent samples
- Uses 'Coupled Self-Attention' layers where pixels in one image can attend to pixels in all other images in the batch, establishing correspondence without explicit encoding
- Creates a large-scale synthetic dataset (S3) of same-subject image clusters using LLMs and existing diffusion models to train this joint distribution capability
Architecture
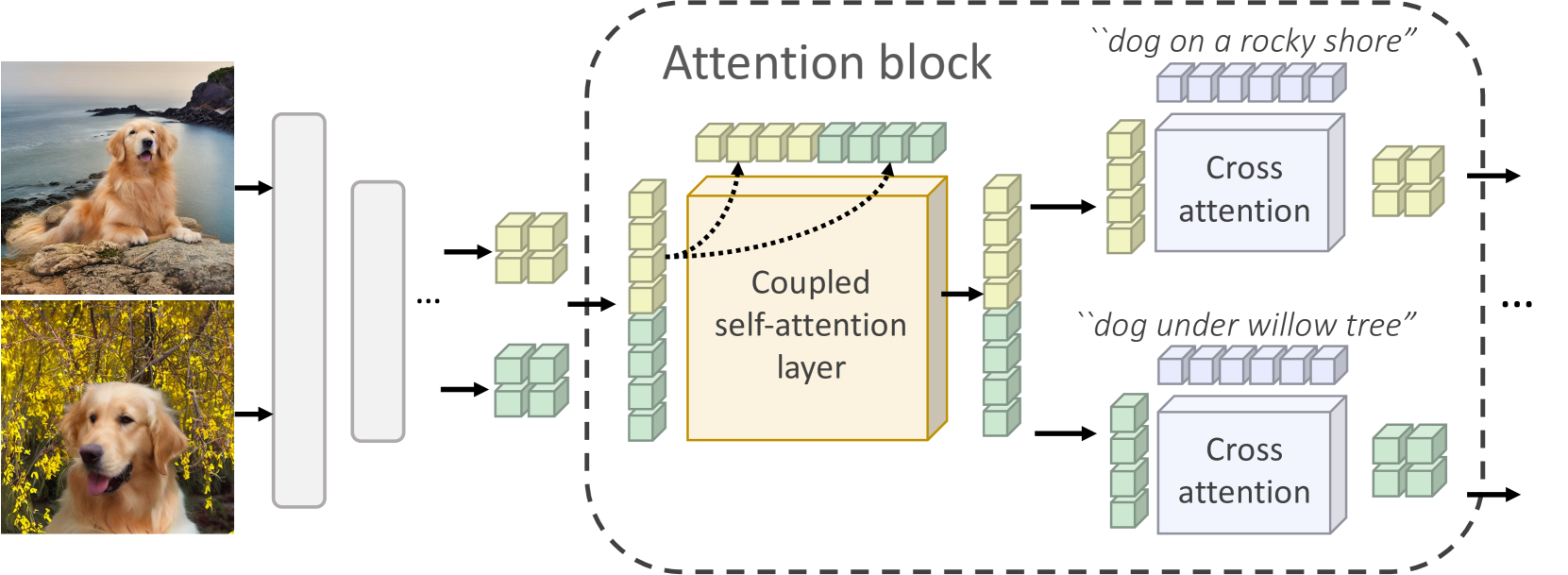
Illustration of the Coupled Self-Attention mechanism compared to standard self-attention.
Evaluation Highlights
- Outperforms finetuning-free baselines (ELITE, BLIP-Diffusion) and even finetuning-based methods (DreamBooth, CustomDiffusion) in subject fidelity metrics
- Achieves higher CLIP-I and DINO scores than DreamBooth on the DreamBooth dataset, indicating better preservation of subject identity
- Generates high-fidelity results using as few as one reference image without any optimization at test time
Breakthrough Assessment
8/10
Significant advance in finetuning-free personalization. By abandoning the encoder bottleneck in favor of joint attention, it solves the identity preservation issue that plagued prior instant customization methods.
