📝 Paper Summary
Personalization of Vision-Language Models
Concept Learning
MyVLM enables frozen vision-language models to recognize and contextualize user-specific concepts by using external detection heads to trigger the injection of learned concept embeddings.
Core Problem
Current VLMs possess generic knowledge (recognizing "a dog") but lack understanding of user-specific concepts (recognizing "your dog"), and fine-tuning them is expensive and prone to forgetting.
Why it matters:
- Users want meaningful interactions reflecting personal experiences (e.g., asking what 'I' am doing in a photo), not just generic descriptions
- Full fine-tuning of large VLMs for every user is computationally prohibitive and degrades general performance (catastrophic forgetting)
- Existing model editing techniques focus on factual edits (e.g., changing capitals) rather than visual concept recognition and contextualization
Concrete Example:
A standard VLM sees an image of a specific person and outputs 'A man sitting on a bench.' MyVLM recognizes the user and outputs 'S* is sitting on a bench,' enabling questions like 'What is S* wearing?'
Key Novelty
Augmenting Frozen VLMs with Concept Heads and Embeddings
- Uses external 'concept heads' (classifiers) as toggles to detect if a specific user-concept is present in the image
- If detected, a learned 'concept embedding' is injected into the VLM's intermediate feature space to guide the language generation
- Keeps the massive VLM backbone completely frozen, ensuring general capabilities are preserved while adding personalization
Architecture
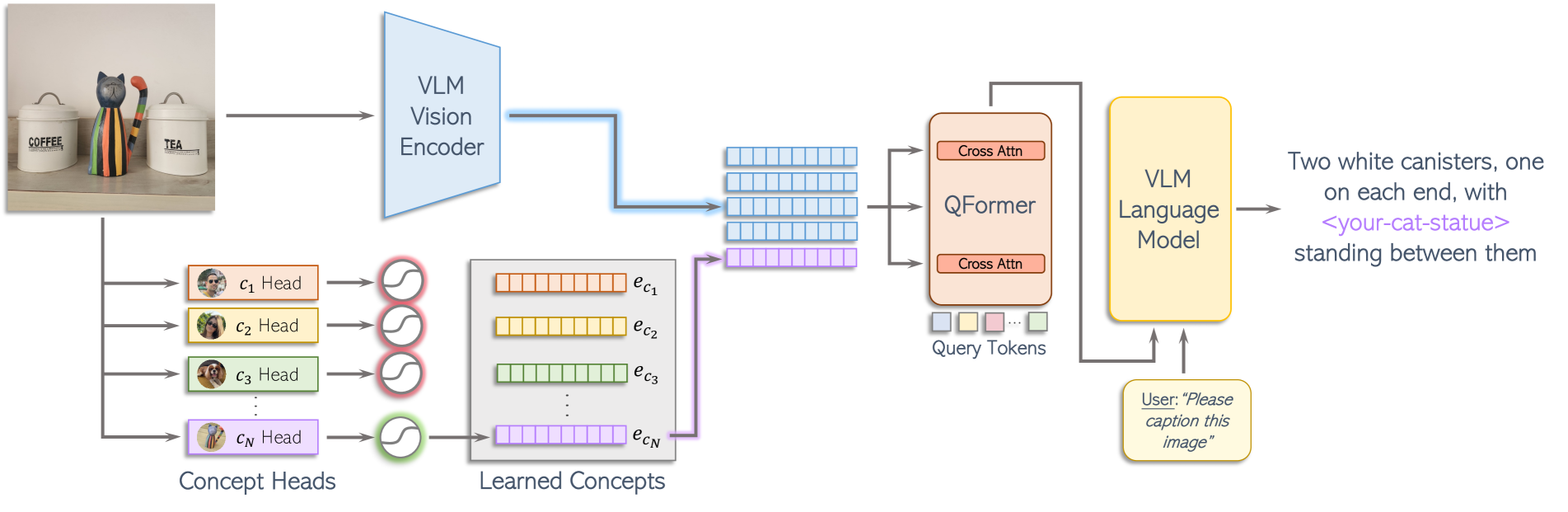
The MyVLM pipeline integration with BLIP-2/LLaVA. It shows the flow from image input to concept detection and embedding injection.
Breakthrough Assessment
7/10
A clever architectural solution effectively separating recognition (heads) from contextualization (embeddings) without fine-tuning the backbone. Addresses a high-value user application (personalization) efficiently.
