📝 Paper Summary
Personalized Text Generation
Long-form Text Generation
Benchmark Creation
LongLaMP introduces a benchmark for personalized long-form text generation across four domains, evaluating models on their ability to maintain user style and coherence in lengthy outputs like emails and reviews.
Core Problem
Existing personalization research focuses on short text (e.g., email subjects), failing to address the complexities of generating long, coherent, and consistent content that reflects a user's style.
Why it matters:
- Real-world applications (emails, reviews, papers) naturally require generating extended passages, not just headlines
- Personalizing long text is computationally difficult and prone to topic drift or style inconsistency over long outputs
- Existing methods like fine-tuning per user suffer from high storage costs and privacy risks
Concrete Example:
In email generation, a model must produce the entire body text matching the sender's specific tone and historical writing style, rather than just predicting a subject line. Generic models fail to capture these user-specific linguistic nuances.
Key Novelty
LongLaMP Benchmark
- Standardizes evaluation for personalized long-text generation using four diverse tasks: Email, Abstract, Review, and Topic Writing
- Introduces two distinct evaluation settings: 'User' (cold start for new users) and 'Temporal' (adapting to known users' evolving style over time)
- Proposes a retrieval-augmented generation (RAG) framework that conditions generation on retrieved user history without expensive per-user fine-tuning
Architecture
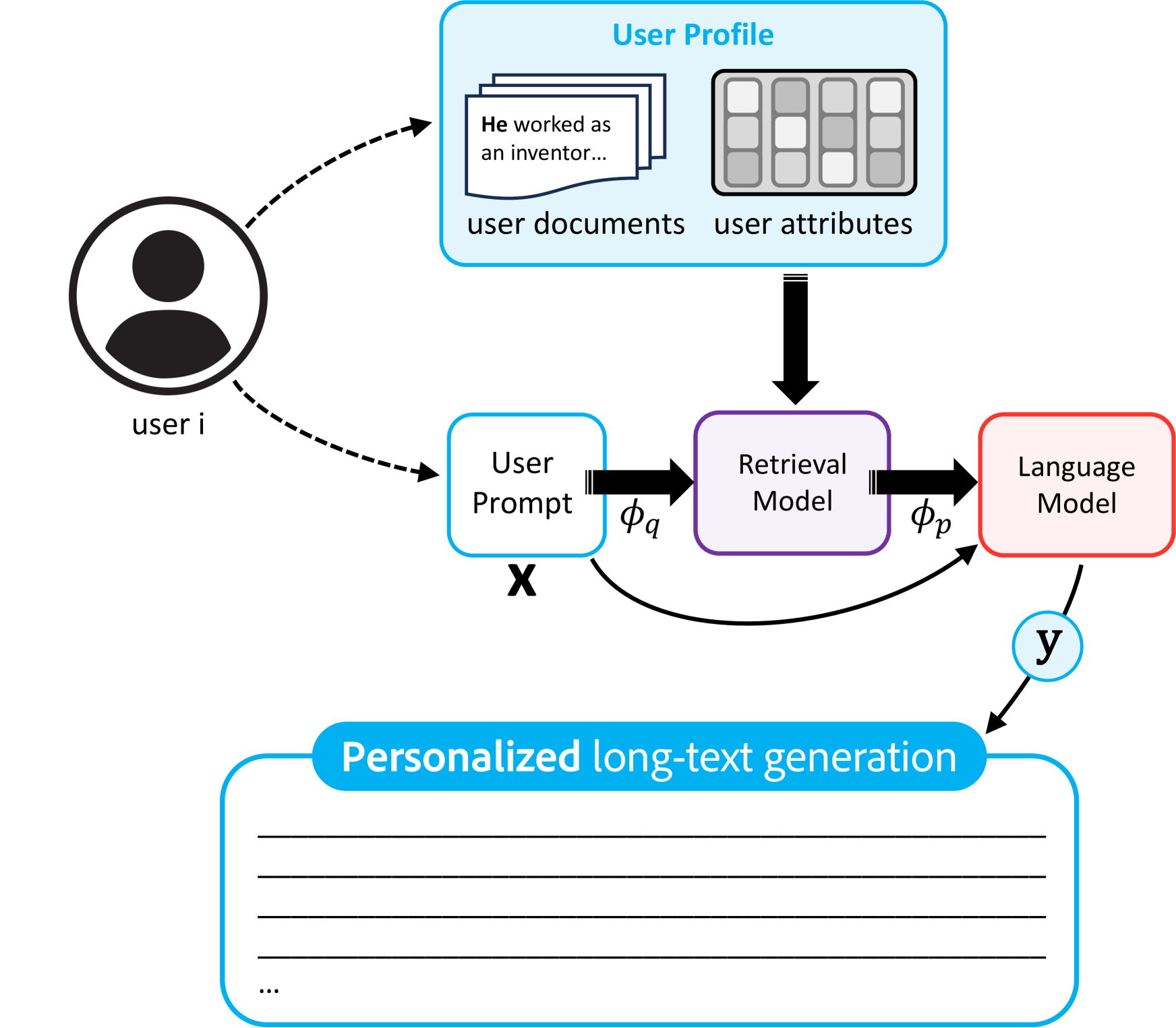
Conceptual diagram of the RAG-based personalization framework (derived from text description)
Evaluation Highlights
- The proposed RAG framework achieves an improvement between 5.7% to 128% across various metrics compared to non-personalized baselines (claimed in intro)
- Constructed 'Personalized Abstract Generation' task with average context length of ~4560 tokens, significantly longer than typical short-text benchmarks
- Established 'Personalized Review Writing' task with ~14,745 training users, providing a large-scale testbed for opinionated long-text generation
Breakthrough Assessment
8/10
Addresses a critical gap (long-form personalization) with a comprehensive, open-source benchmark. Shifts focus from trivial personalization (titles) to complex content generation.