📝 Paper Summary
Personalized Image Generation
Subject-Driven Generation
By exploiting the disentangled positional encodings in Diffusion Transformers, this framework achieves training-free personalization via timestep-adaptive token replacement and patch perturbation, overcoming the limitations of attention sharing.
Core Problem
Existing training-free personalization methods (like attention sharing) fail when applied to Diffusion Transformers (DiTs) because DiT's explicit positional encodings cause destructive interference and 'ghosting' artifacts.
Why it matters:
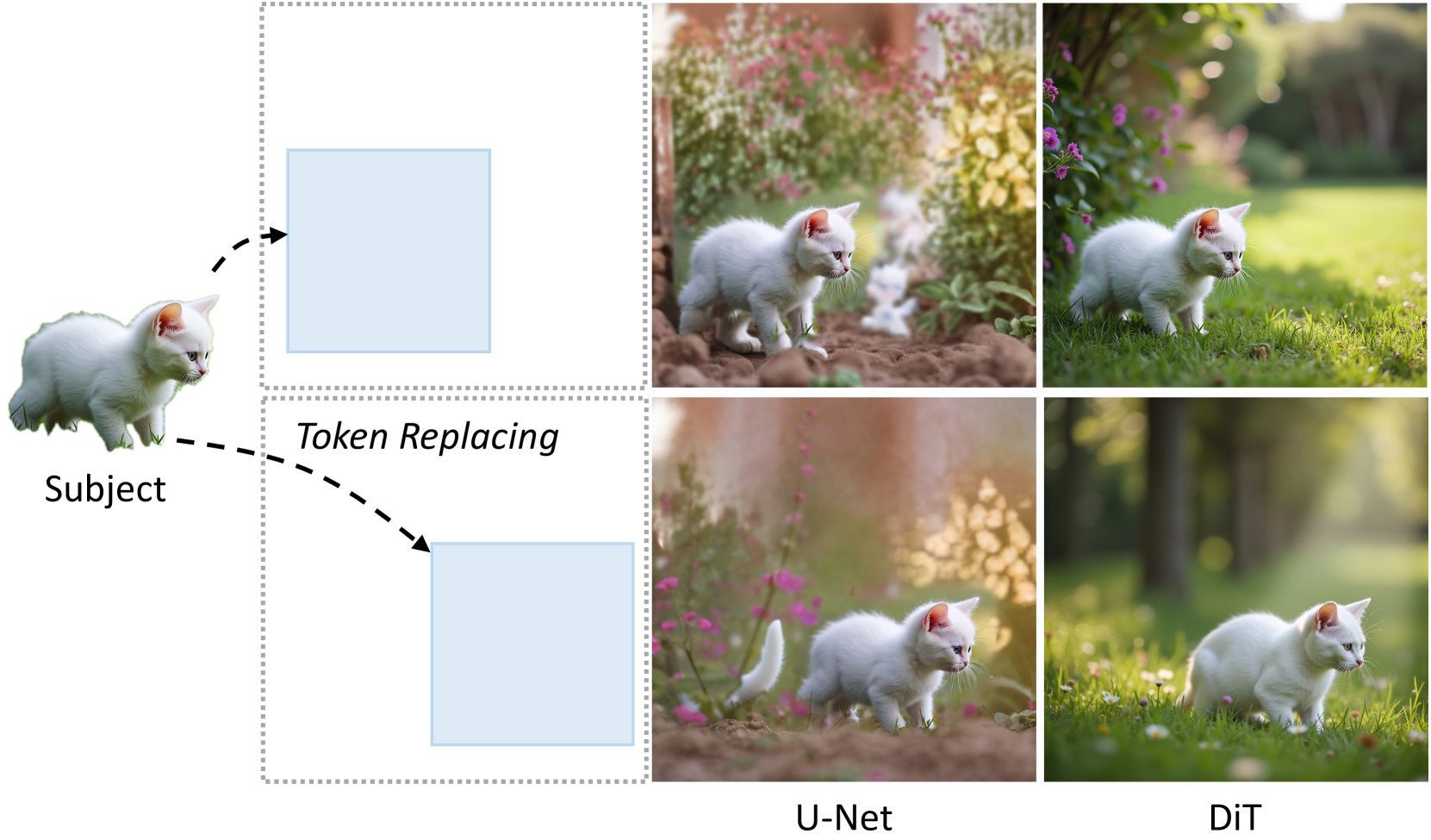
- Traditional U-Net personalization methods do not transfer to state-of-the-art DiT architectures, limiting scalability
- Fine-tuning methods (DreamBooth, LoRA) are computationally expensive and slow (requires optimization steps)
- Naive attention sharing in DiTs forces generated tokens to over-attend to reference tokens at identical coordinates due to Rotational Positional Encoding (RoPE) sensitivity
Concrete Example:
When applying standard attention sharing to a DiT, concatenating denoising and reference tokens results in 'ghosting artifacts' where the reference subject appears translucently in the generated image at its original coordinate. This happens because the attention mechanism in DiT is heavily biased by position.
Key Novelty
Personalize Anything Framework
- Leverages DiT's 'position-disentangled' property: unlike U-Net, DiT allows replacing semantic tokens directly without positional conflicts, enabling zero-shot reconstruction
- Timestep-Adaptive Strategy: Uses physical token replacement in early denoising steps to anchor identity, then switches to multi-modal attention in later steps for semantic flexibility
- Patch Perturbation: Locally shuffles reference tokens and augments masks (erosion/dilation) to prevent texture overfitting and encourage global feature learning
Architecture
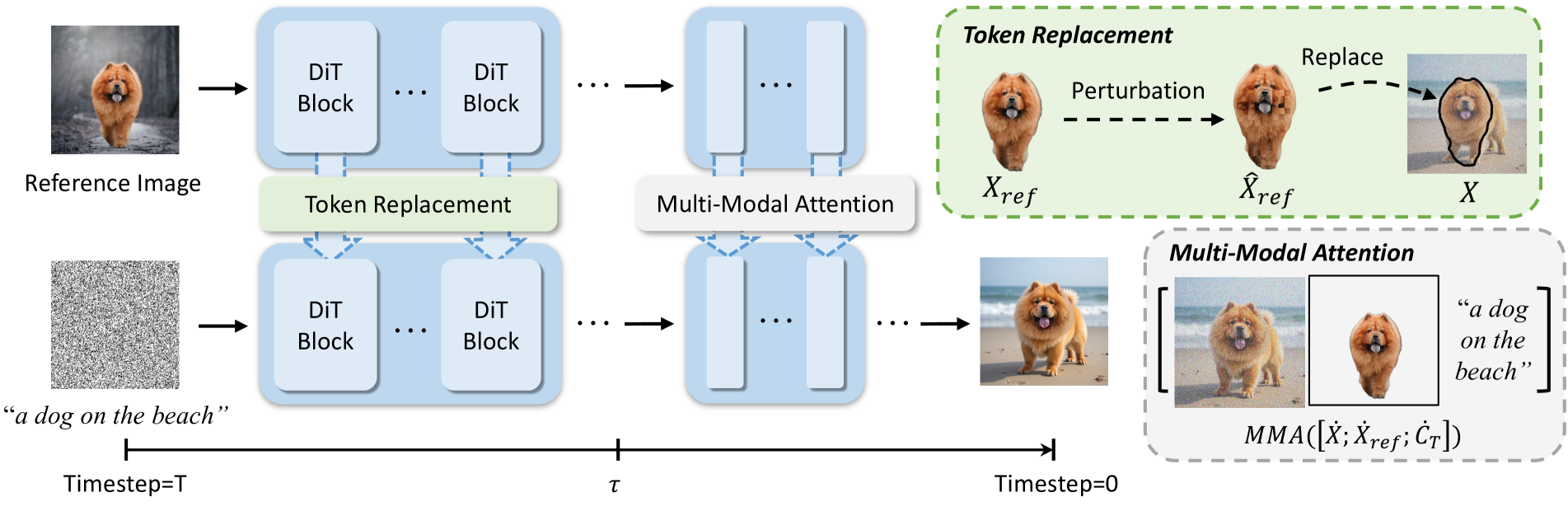
The 'Personalize Anything' framework pipeline, illustrating the inversion, perturbation, and timestep-adaptive denoising process.
Evaluation Highlights
- Attention scores between denoising and reference tokens at the same position are 723% higher in DiT than in U-Net, quantitatively proving DiT's extreme position sensitivity
- Demonstrates high-fidelity subject reconstruction via simple token replacement, where U-Net baselines fail with blurred edges and artifacts
- Enables zero-shot applications including layout-guided generation, multi-subject composition, and inpainting without any model fine-tuning
Breakthrough Assessment
8/10
Identifies a fundamental architectural blocker in applying personalization to DiTs (positional encoding collision) and provides a tailored, training-free solution that exploits DiT's unique properties.