📝 Paper Summary
Modularized RAG pipeline
Query rewriting / query generation
The paper identifies that LLMs often fail to answer semantically equivalent questions consistently and proposes a Retrieval-Augmented Generation method using retrieved similar questions to improve both accuracy and coherence.
Core Problem
LLMs suffer from instability and lack of coherence, meaning they often generate different (and sometimes incorrect) outputs when given diverse but semantically equivalent lexical variations of the same question.
Why it matters:
- Inconsistency erodes user trust; a model should answer 'What is Italy's capital?' and 'Name the capital of Italy' identically.
- Previous black-box prompt engineering attempts to fix stability are ad-hoc; a principled approach is needed to help models access their parametric knowledge reliability.
- Standard RAG retrieves documents, but this paper argues retrieving *similar questions* triggers different semantic patterns that help the model 'understand' the request better.
Concrete Example:
A model might correctly answer 'How old was jacqueline wilson when her first book got published?' but fail on 'What was the age of Jacqueline Wilson when she experienced the publication of her initial book?', indicating a failure to access knowledge due to phrasing.
Key Novelty
Question-RAG (q-RAG) / Question Prompting
- Instead of retrieving documents (standard RAG), retrieve semantically equivalent questions (Support Questions) from a large pre-computed index.
- Feed these retrieved questions (and optionally their pre-computed answers) into the LLM context to help it 'disambiguate' the intent and trigger the correct parametric knowledge.
- Use redundant information (question variations) to stabilize the model's understanding rather than just adding missing facts.
Architecture
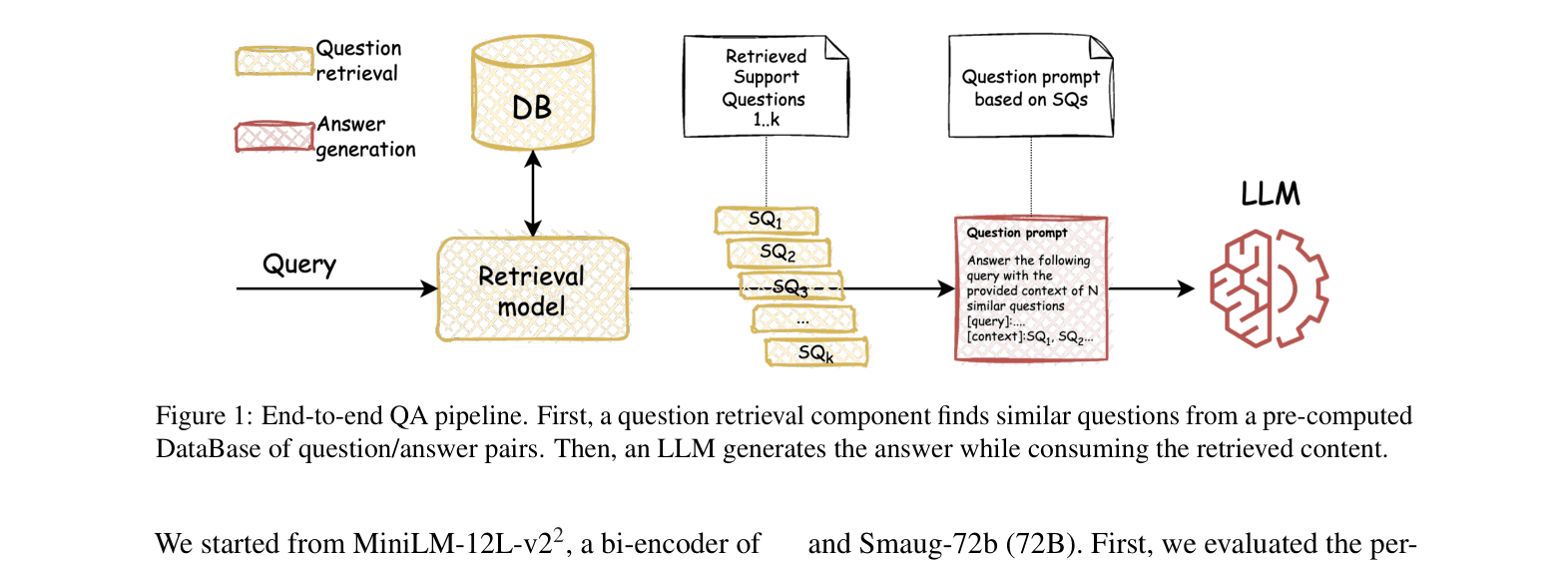
The end-to-end QA pipeline illustrating the Question-RAG approach.
Evaluation Highlights
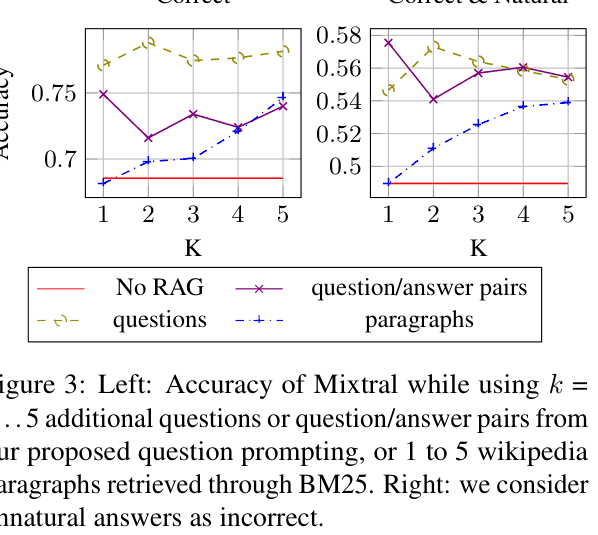
- Question-RAG leads to a 4-8 percentage point improvement in end-to-end performance on factual QA tasks compared to standard prompting.
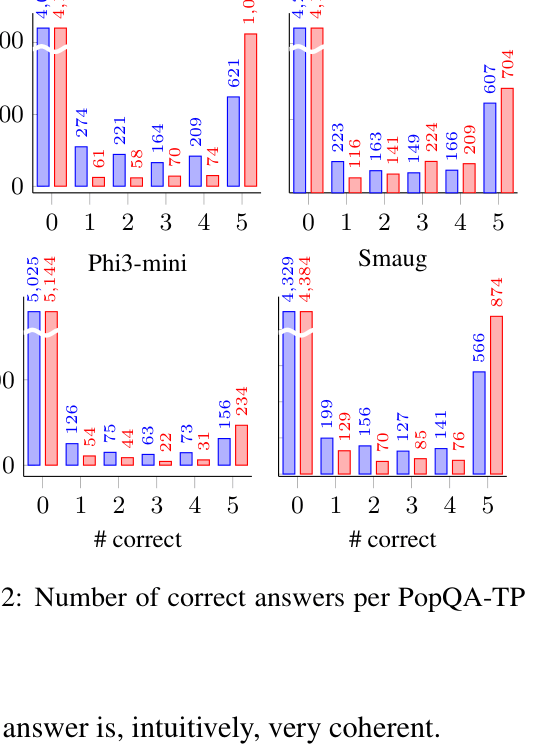
- On PopQA-TP, coherence (semantic similarity of answers across variations) improved significantly: Mixtral-8x7B went from 53.21 to 81.21.
- Llama2-70b accuracy on PopQA-TP increased from 54.20% (base) to 62.73% (question prompt).
Breakthrough Assessment
7/10
Simple yet effective insight: retrieving similar questions helps LLM 'understanding' more than just retrieving facts. Strong empirical gains on coherence, though the method relies on a massive pre-indexed question database.