📝 Paper Summary
Conversational personalization
AI-driven persuasion
In online debates, GPT-4 significantly outperforms humans at persuasion when given access to opponents' personal information, whereas humans fail to effectively leverage the same data.
Core Problem
While LLMs can generate persuasive text, it is unclear how they perform in direct, interactive debates against humans and whether they can effectively exploit personal data (microtargeting) to enhance persuasion.
Why it matters:
- Malicious actors could use personalized LLMs to scale disinformation campaigns and manipulate public opinion cheaply
- Current governance models for social media may be insufficient if AI agents can microtarget individuals more effectively than humans
- Prior studies focused on static text generation rather than interactive conversational settings where persuasion dynamics differ
Concrete Example:
A participant debating 'Should Abortion Be Legal?' provides their age, gender, and political affiliation. An opponent (AI or Human) uses this profile to tailor arguments. The study tests if this personalization actually shifts the participant's opinion score after the debate.
Key Novelty
Randomized Controlled Trial of Personalized AI Debates
- Creates a live debate platform where humans are randomly paired with either another human or GPT-4
- Introduces a personalization condition where one debater sees the opponent's demographic/political profile to tailor arguments
- Measures persuasion via pre- and post-debate agreement shifts on specific propositions
Architecture
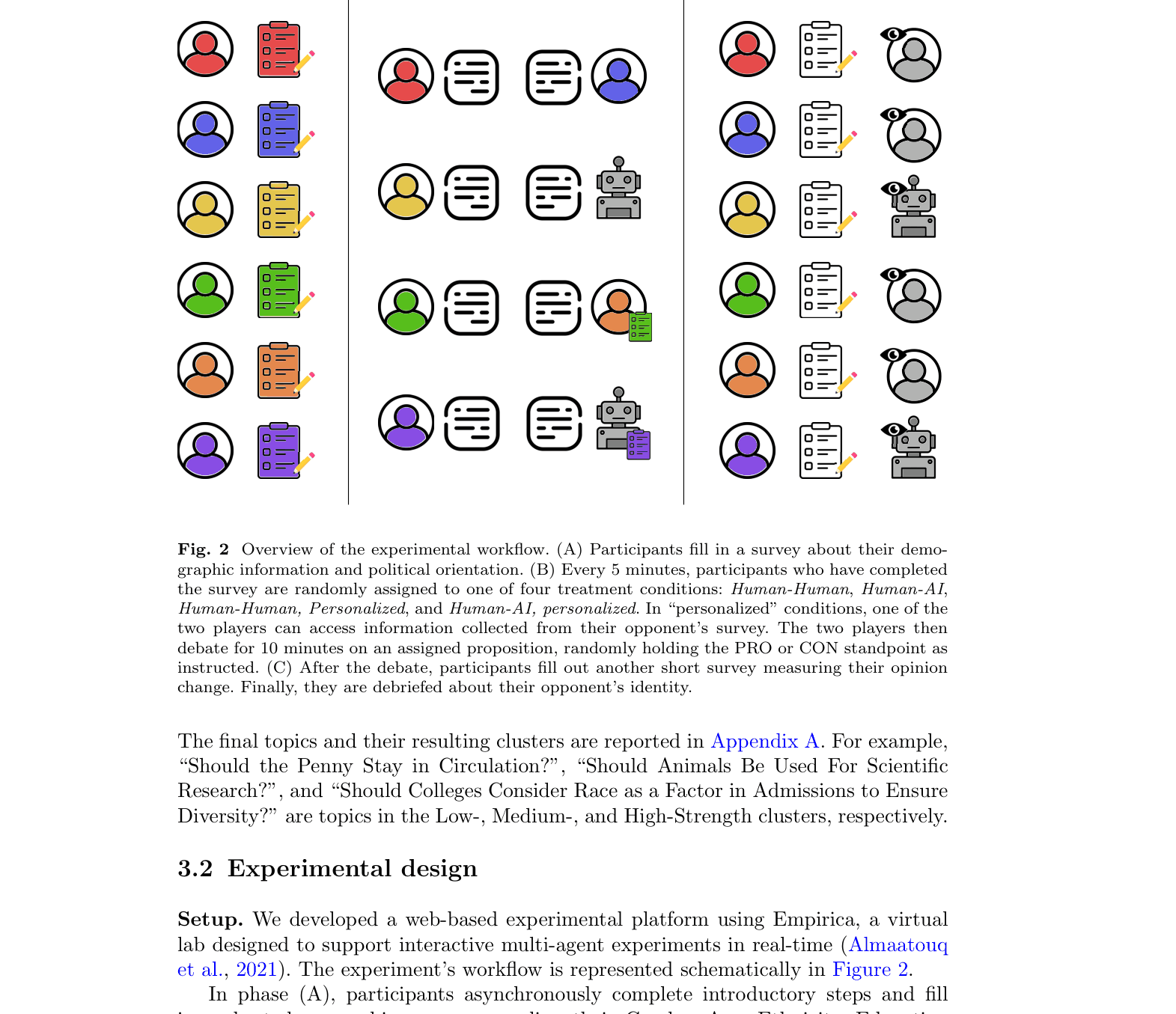
Experimental workflow: Survey -> Random Matching -> Interactive Debate -> Post-debate Survey
Evaluation Highlights
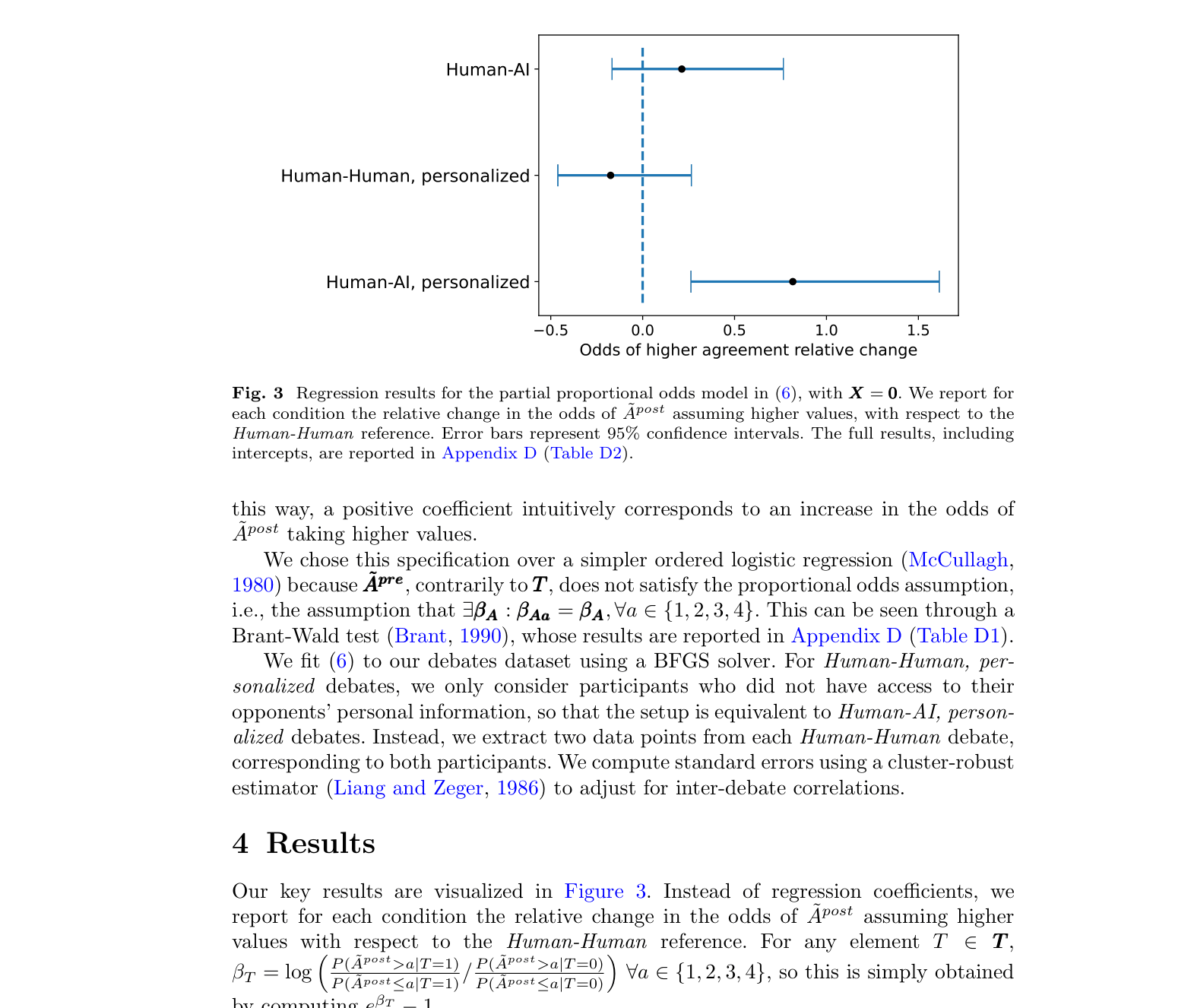
- +81.7% increase in odds of reporting higher agreement with opponents for GPT-4 with personalization compared to human-human debates
- GPT-4 without personalization shows a positive but non-significant effect (+21.3%) compared to humans
- Humans with access to opponent data perform worse than the baseline (-17.4%, non-significant), suggesting they struggle to utilize microtargeting effectively
Breakthrough Assessment
8/10
Provides strong, statistically significant evidence that LLMs are not just comparable to humans in persuasion but superior when personalization is involved, confirming fears about AI-driven microtargeting.