📝 Paper Summary
Personalized Segmentation
One-shot Learning
Foundation Model Adaptation
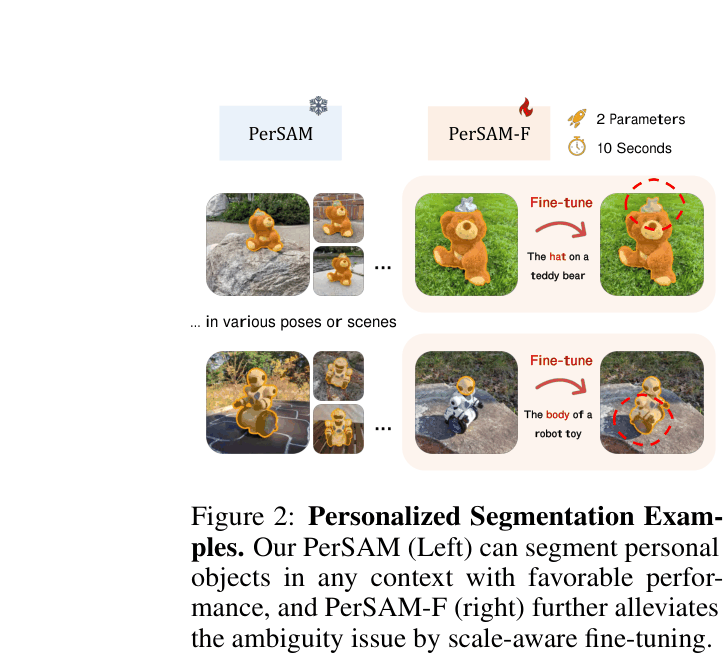
PerSAM customizes the Segment Anything Model (SAM) for specific visual concepts using a single reference image-mask pair via training-free attention guidance and efficient 2-parameter fine-tuning.
Core Problem
The vanilla Segment Anything Model (SAM) is a generalist that requires manual prompting for every image and lacks the ability to automatically segment a specific personal concept (e.g., 'my pet dog') across different contexts.
Why it matters:
- Manually prompting SAM for every image in a large collection is labor-intensive and time-consuming
- Generalist models often fail to distinguish specific instances from visually similar objects or backgrounds without instance-specific semantic cues
- Subject-driven generation (like DreamBooth) suffers when background visual information leaks into the learned subject representation
Concrete Example:
When trying to segment a specific 'teapot' that has a lid and body, standard SAM might ambiguously segment just the lid or the whole pot. PerSAM-F learns to weight these scales correctly from a single reference, whereas vanilla SAM requires manual selection for each new image.
Key Novelty
Training-free Attention Guidance & Scale-Aware Fine-Tuning
- Training-free PerSAM: Uses a location confidence map derived from the reference image to guide SAM's internal cross-attention, focusing the model on the target object's features
- PerSAM-F (Fine-tuning): Freezes the entire SAM and tunes only 2 parameters (weights for multi-scale masks) to resolve ambiguity between object parts and wholes, taking just 10 seconds
- Target-Semantic Prompting: Injects high-level visual embeddings of the target object directly into prompt tokens to supplement SAM's low-level positional cues
Architecture
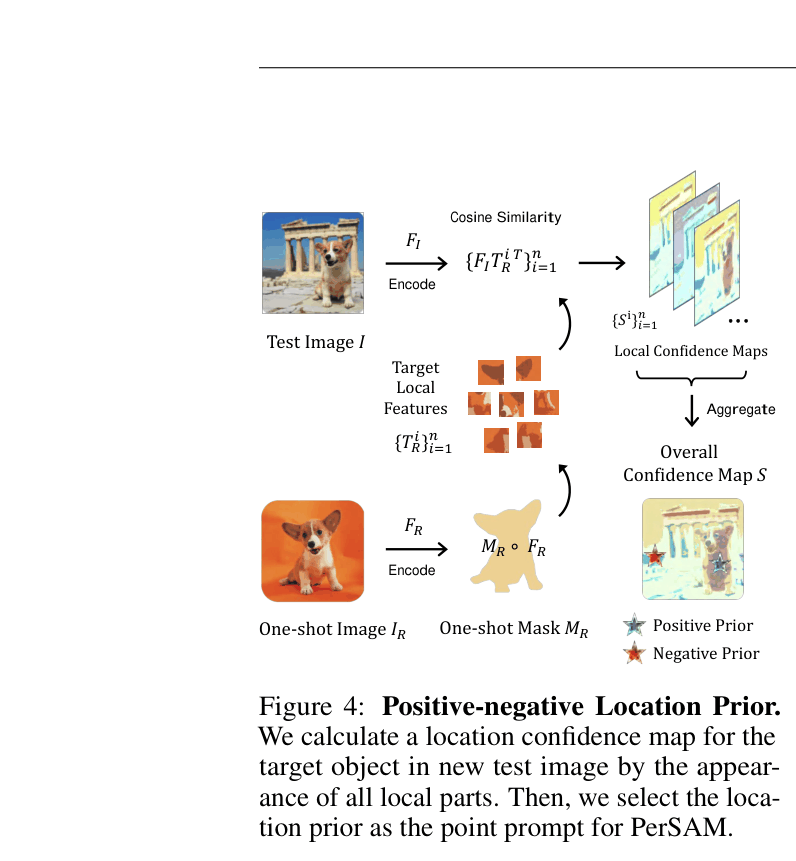
The complete pipeline: (1) extracting location priors (confidence map) from the reference, (2) injecting target semantics via attention guidance and prompting into SAM's decoder.
Evaluation Highlights
- PerSAM-F achieves 95.3% mIoU on the new PerSeg dataset, outperforming the large-scale specialist SegGPT (94.3%) while using only 2 learnable parameters
- Training-free PerSAM improves over in-context learner Painter by +32.3% J&F score on video object segmentation (DAVIS 2017)
- PerSAM-F fine-tuning takes only 10 seconds on a single A100 GPU, compared to hours for full model tuning
Breakthrough Assessment
8/10
Highly efficient adaptation of a foundation model. The 2-parameter fine-tuning is extremely lightweight yet effective, and the application to improving DreamBooth adds practical value.