📝 Paper Summary
Text-to-Image Generation
Model Personalization
Parameter-Efficient Fine-Tuning (PEFT)
SVDiff adapts text-to-image diffusion models by fine-tuning only the singular values of weight matrices, drastically reducing model storage while mitigating overfitting and enabling better multi-subject generation.
Core Problem
Fine-tuning large diffusion models for personalization requires storing massive checkpoints (e.g., 3.66GB) and often suffers from overfitting, language drift, or the inability to disentangle multiple subjects.
Why it matters:
- Full-weight fine-tuning (like DreamBooth) is storage-inefficient for users who want to save many personalized models
- Models often fail to learn multiple concepts simultaneously, mixing styles (e.g., blending a dog and a sculpture) or losing the ability to edit an image without destroying its identity
- Overfitting to few-shot examples degrades the model's generalizability, making it hard to place subjects in new contexts
Concrete Example:
When fine-tuning a model on both a 'dog' and a 'sculpture', standard approaches often generate a 'sculpture-like dog'. SVDiff with Cut-Mix-Unmix successfully generates a distinct dog sitting beside a sculpture.
Key Novelty
Spectral Shift Fine-Tuning & Cut-Mix-Unmix Augmentation
- Decompose weight matrices via SVD (Singular Value Decomposition) and freeze the singular vectors, training only the singular values (spectral shifts) to adapt the model
- Introduce 'Cut-Mix-Unmix', a data augmentation strategy that constructs collage images (e.g., cut-and-paste) to explicitly teach the model to separate styles/concepts spatially
Architecture
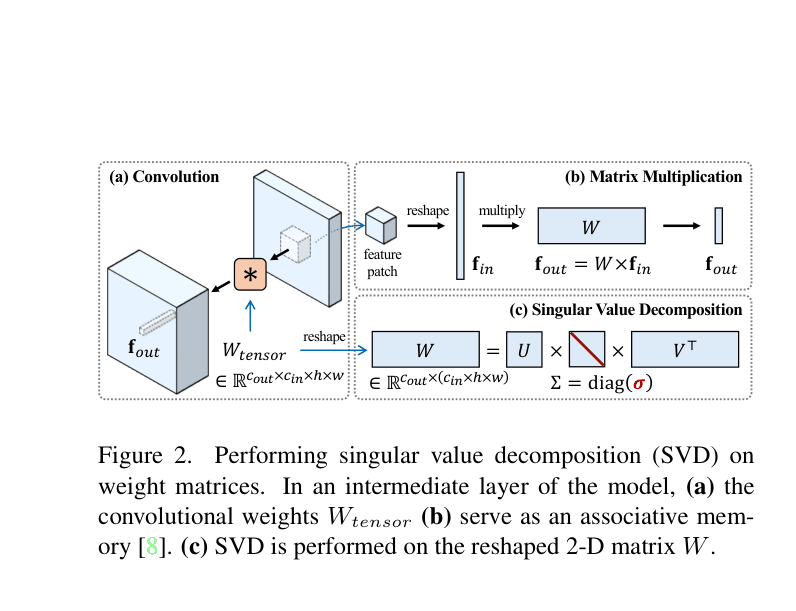
The SVD-based parameterization process. It shows how a convolutional weight tensor is reshaped into a matrix, decomposed into U, Sigma, V, and how only Sigma (singular values) is fine-tuned.
Evaluation Highlights
- Reduces checkpoint size to ~1.7MB per subject (vs. 3.66GB for vanilla DreamBooth on Stable Diffusion), a ~2,200x reduction
- Achieves 60.9% user preference over full-weight fine-tuning for multi-subject generation quality (consistency and disentanglement)
- Maintains comparable text-alignment (CLIP score) and image-alignment (LPIPS) to full fine-tuning while significantly outperforming Custom Diffusion in subject fidelity
Breakthrough Assessment
8/10
Offers a highly practical, storage-efficient solution for personalization that rivals full fine-tuning quality. The Cut-Mix-Unmix technique effectively solves the persistent multi-subject blending problem.