📝 Paper Summary
Personalized Large Language Models (PLLMs)
User Modeling
This survey establishes a unified framework for Personalized Large Language Models (PLLMs), categorizing techniques into input-level prompting, model-level adaptation, and objective-level alignment to address user-specific needs.
Core Problem
General LLMs suffer from a lack of personalization, failing to understand individual emotions, writing styles, and historical contexts, which limits their effectiveness in user-centric applications.
Why it matters:
- Conversational agents without personalization cannot adapt to a user's preferred tone or recall past interactions, leading to generic and repetitive responses
- Lack of personalization hinders the application of LLMs in domains requiring specific context, such as healthcare, finance, and education
- Existing research is fragmented; a systematic review is needed to consolidate advancements in representing diverse user data and managing long-term memories
Concrete Example:
A standard LLM answering a medical question might give generic advice, whereas a Personalized LLM (PLLM) would incorporate the user's specific medical history and profile (e.g., 'A, 18, student') to provide a tailored response.
Key Novelty
Three-Level Personalization Taxonomy
- Formalizes personalization into three technical levels: Input-level (injecting user context via prompts), Model-level (fine-tuning parameters for specific users), and Objective-level (aligning loss functions with user preferences)
- Classifies user queries into Extraction (factual lookup), Abstraction (summarizing user profiles), and Generalization (dynamic inference with external knowledge), distinct from simple role-play
Architecture
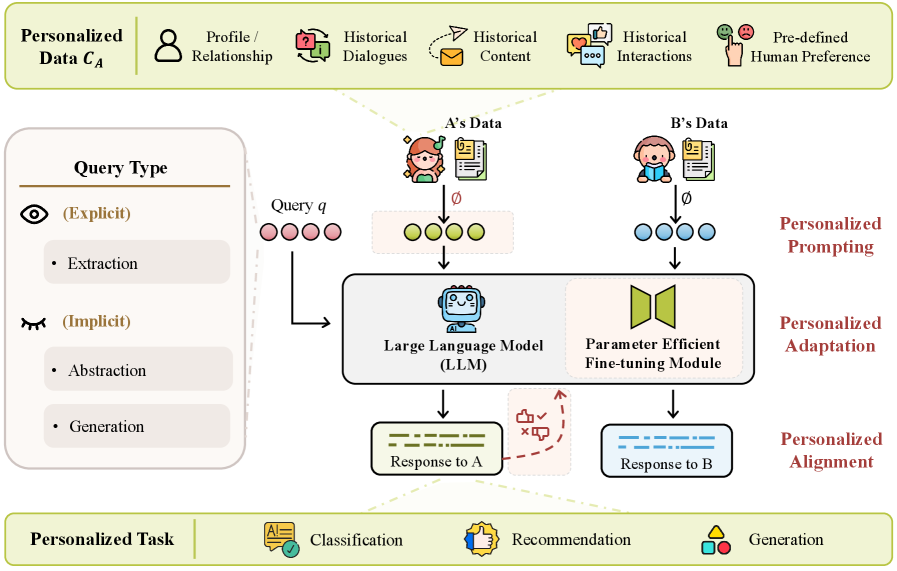
A taxonomy of Personalized Large Language Models (PLLMs) categorized by the three levels of personalization techniques.
Evaluation Highlights
- Provides a structured taxonomy rather than empirical results; benchmarks are categorized by query type (Extraction, Abstraction, Generalization)
- Systematically reviews methods for handling profile augmentation, retrieval augmentation, and soft-fused prompting
Breakthrough Assessment
7/10
A comprehensive survey that provides a necessary structured framework and mathematical formulation for the growing field of Personalized LLMs, though it is a review rather than a new method.