📝 Paper Summary
Dynamic User Profiling
Long-context Memory
Personalized Dialogue Systems
PersonaMem is a benchmark for evaluating whether LLMs can track evolving user personas over long interaction histories, revealing that frontier models achieve only ~50% accuracy in personalized response selection.
Core Problem
LLMs struggle to track evolving user traits and preferences (personas) over long-term interaction histories, failing to update their internal user profile when new events contradict or refine past information.
Why it matters:
- Users perceive chatbots as less empathetic and helpful when they fail to remember or adapt to life changes (e.g., new allergies, changed marital status)
- Static user profiles are insufficient because real-world user preferences are dynamic and ever-changing over time
- Existing benchmarks often focus on static fact retrieval rather than the dynamic evolution of user characteristics across different scenarios
Concrete Example:
A user initially tells the chatbot 'I like pizza.' In a later session, they mention, 'I've started exploring gluten-free options' due to an allergy. When subsequently asked for food recommendations, a non-personalized LLM suggests standard pizza, failing to incorporate the recent health update.
Key Novelty
PersonaMem Benchmark
- Constructs synthetic, long-context interaction histories where user personas evolve chronologically based on simulated life events (e.g., job changes, health issues)
- Evaluates personalization via 'in-situ' user queries across 7 types (e.g., suggesting new ideas, revisiting reasons for change) that require understanding the user's *current* state
- Uses a modular generation pipeline to create coherent, multi-session histories (up to 1M tokens) that maintain causal consistency across diverse topics like therapy and travel
Architecture

Overview of the PersonaMem benchmark construction and evaluation concept.
Evaluation Highlights
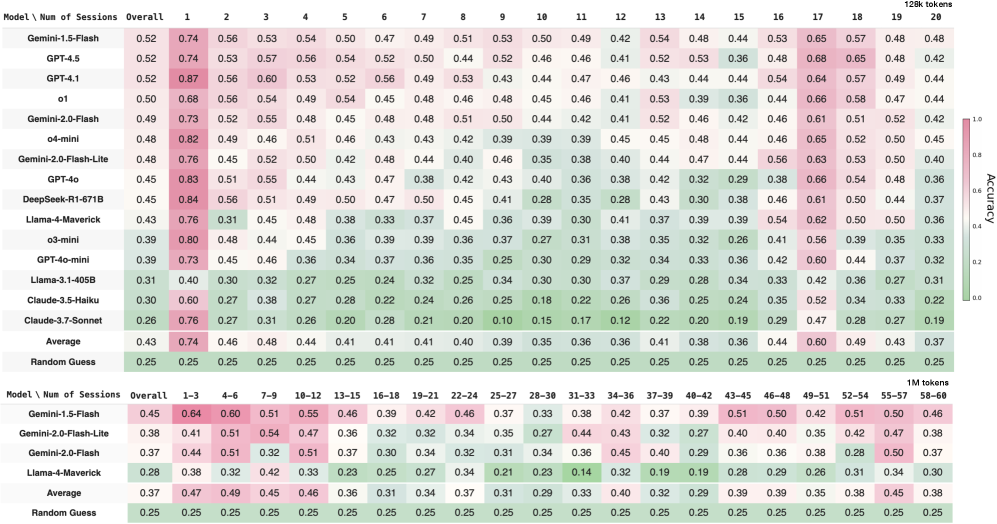
- Frontier models (GPT-4.5, Gemini-1.5, o1) achieve only ~50% accuracy on multiple-choice personalization tasks, barely outperforming the 25% random chance baseline given the difficulty of distractors
- Llama-4-Maverick scores lower at 43% overall accuracy, indicating significant room for improvement in open-weights models
- Models perform well on recalling static facts (60–70% accuracy) but fail significantly when asked to incorporate the user's latest situation into new suggestions (30–50% accuracy)
Breakthrough Assessment
8/10
Provides a crucial, realistic benchmark for a major gap in current LLM capabilities (dynamic personalization). The rigorous timeline-based construction and poor performance of SOTA models highlight a significant unsolved problem.