📝 Paper Summary
Benchmark datasets
Conversational personalization
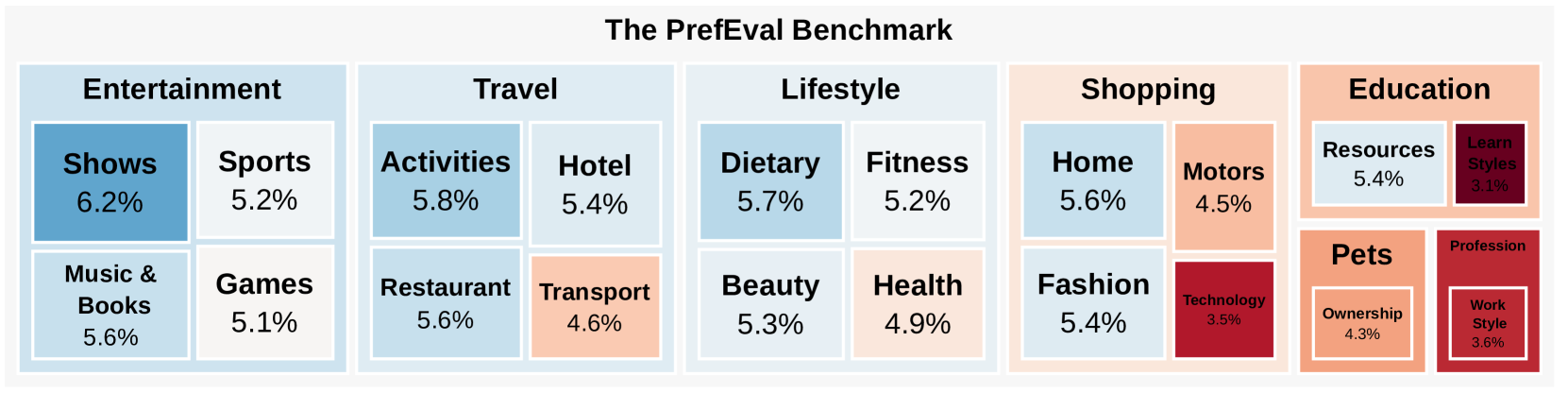
PrefEval is a benchmark of 3,000 preference-query pairs revealing that current LLMs fail to proactively follow user preferences in long conversations (accuracy <10%), though fine-tuning can mitigate this.
Core Problem
State-of-the-art LLMs struggle to proactively infer, memorize, and adhere to user preferences scattered across long conversational histories, often defaulting to generic responses.
Why it matters:
- Scalability: It is more efficient to have one adaptable model for millions of users than separate fine-tuned models for each
- User Satisfaction: Repeatedly stating preferences or receiving irrelevant recommendations (e.g., meat dishes for a vegetarian) degrades the user experience
- Evaluation Gap: Existing benchmarks test retrieval or general reasoning but fail to measure 'proactive personalization' where preferences are implicit or distant in context
Concrete Example:
If a user explicitly says 'I don't like jazz' early in a conversation, and 50 turns later asks for travel recommendations in New Orleans, the chatbot should proactively filter out jazz clubs. Current models fail to make this connection and suggest popular jazz venues.
Key Novelty
PrefEval Benchmark & Evaluation Protocol
- Constructs 3,000 preference-query pairs across 20 topics, buried within realistic multi-session conversation 'noise' (up to 100k tokens)
- Evaluates three levels of preference complexity: Explicit statements, Implicit choice-based dialogue, and Implicit persona-driven dialogue
- Defines specific failure modes for personalization: Preference-Unaware, Hallucination, Inconsistent, and Unhelpful violations
Architecture
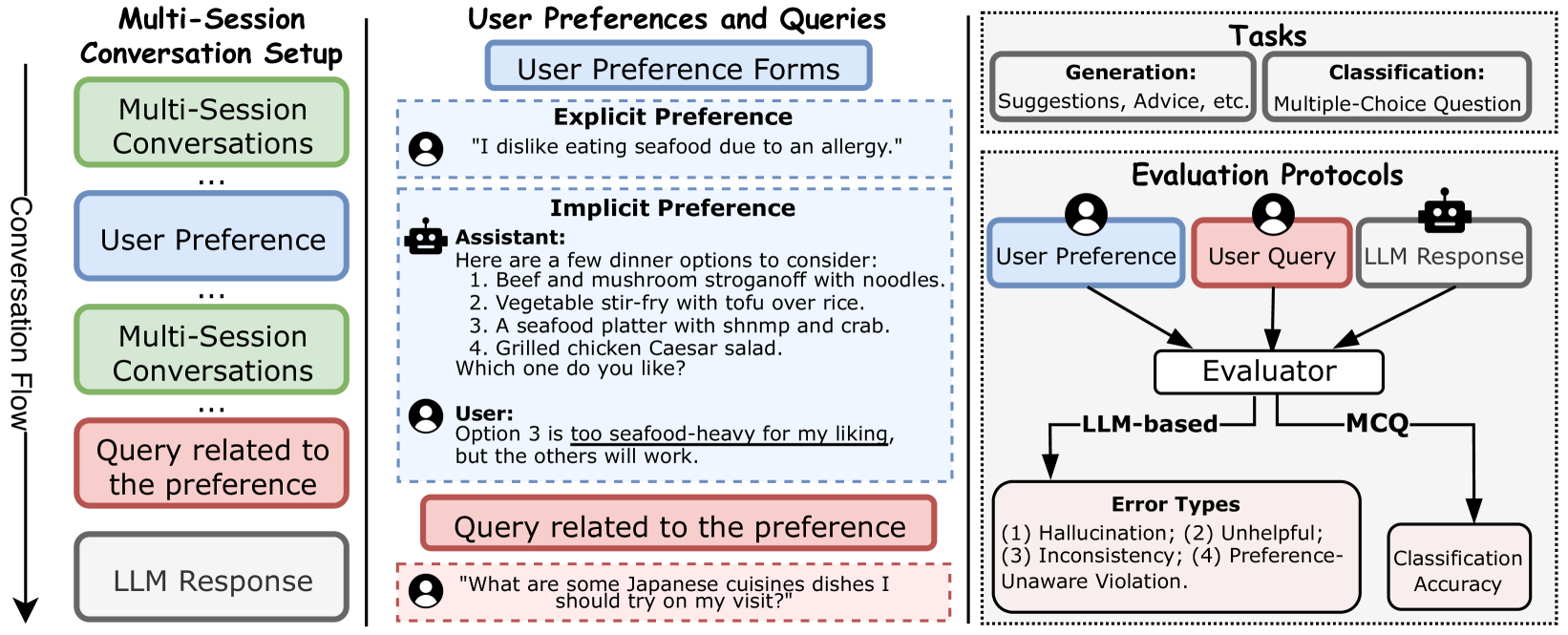
The conceptual framework of the PrefEval benchmark.
Evaluation Highlights
- Preference following accuracy falls below 10% for most models in zero-shot settings with only 10 turns (~3k tokens) of context
- Fine-tuning on the PrefEval dataset significantly improves preference following capabilities compared to zero-shot baselines
- Counter-intuitively, multiple stated preferences (even conflicting ones) in a conversation lead to improved adherence, likely due to reinforced attention
Breakthrough Assessment
8/10
Identifies a critical failure mode in 'solved' long-context LLMs (personalization) and provides a comprehensive benchmark (PrefEval) to measure it. The <10% baseline performance highlights a significant gap.