📝 Paper Summary
Text-to-Video Generation
Video-to-Audio Generation
Video Editing
Video Personalization
Movie Gen demonstrates that scaling standard Transformers with Flow Matching to 30B parameters achieves state-of-the-art results in HD video generation, personalization, editing, and synchronized audio without complex diffusion schedules.
Core Problem
Current commercial video generation systems often lack integrated capabilities for precise editing and personalization, and rely on complex diffusion noise schedules that are difficult to tune.
Why it matters:
- Human imagination seamlessly composes motion, physics, and audio, but AI models typically treat these as separate, disconnected tasks.
- Existing video models often struggle with temporal consistency and precise instruction-following (e.g., editing a specific object without changing the background).
- Standard diffusion models do not guarantee zero terminal signal-to-noise ratio, requiring ad-hoc modifications for video generation.
Concrete Example:
A user wants to generate a video of a specific person (personalization) and then 'add tinsel streamers to the lantern' (editing). Current systems might generate a random person or completely alter the scene composition when attempting the edit, whereas Movie Gen preserves identity and scene structure.
Key Novelty
Unified Scaling of Simple Flow Matching Transformers
- Replaces complex diffusion schedules with Flow Matching, which naturally ensures zero terminal signal-to-noise ratio and simplifies training large-scale media models.
- Employs a 'cast' of specialized but compatible foundation models (Video, Audio, Personalization, Editing) rather than a single monolithic black box.
- Utilizes a massive 30B parameter Transformer backbone (Movie Gen Video) trained on internet-scale data, proving simple architectures scale effectively for video.
Architecture
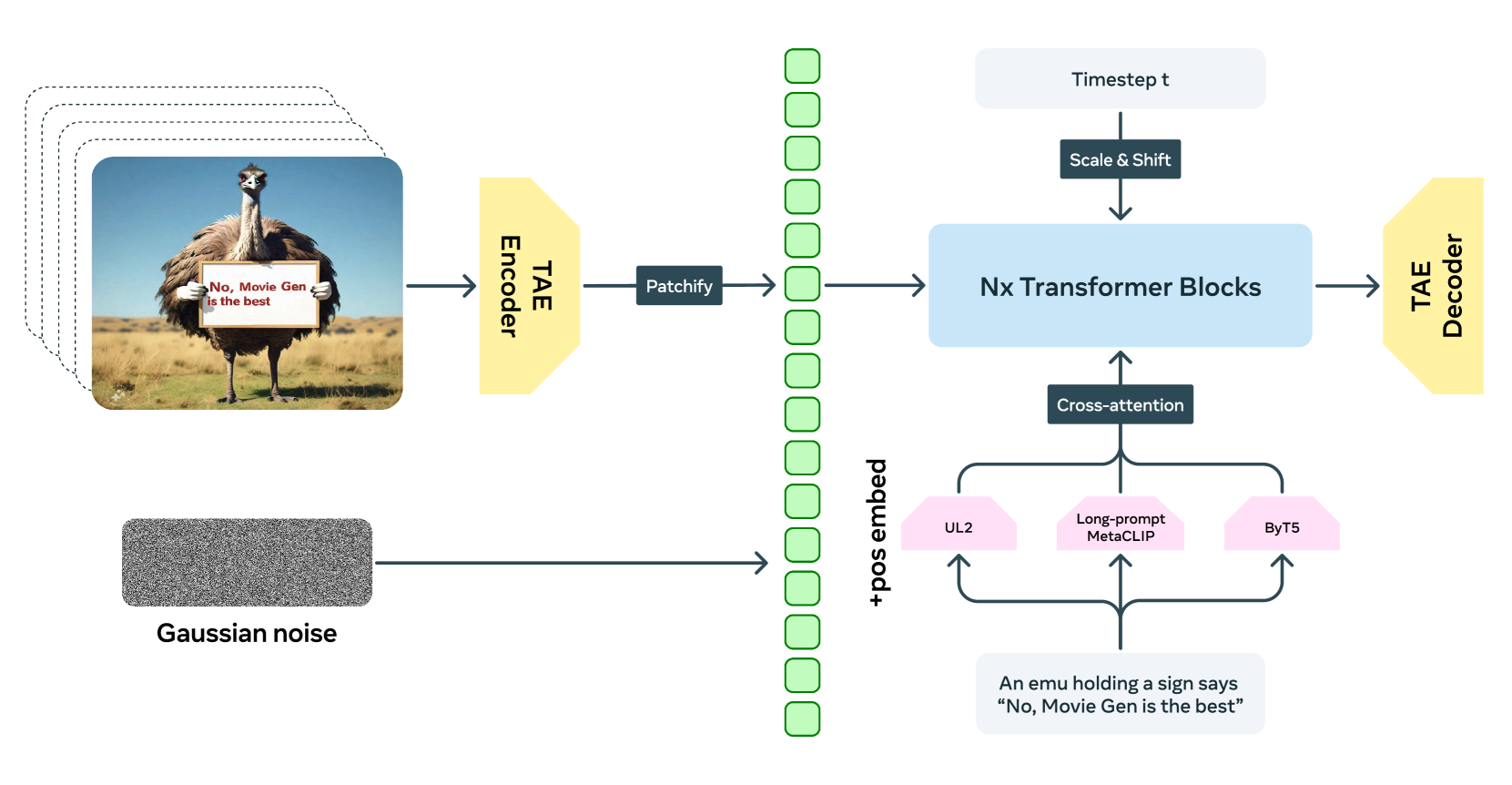
The joint image and video generation pipeline using Flow Matching and Temporal Autoencoder (TAE).
Evaluation Highlights
- Scales text-to-video generation to 30B parameters, supporting 1080p HD video at 16 frames-per-second for up to 16 seconds.
- Generates 48kHz high-quality cinematic audio (sound effects and music) synchronized with video using a 13B parameter audio model.
- Achieves state-of-the-art performance claims against Runway Gen3, LumaLabs, and OpenAI Sora on overall video quality (specific scores not in snippet).
Breakthrough Assessment
9/10
A massive engineering feat scaling video generation to 30B parameters with comprehensive capabilities (audio, editing, personalization) that matches or exceeds top commercial systems.
