📝 Paper Summary
Video Generation
Text-to-Video
Personalization
AnimateDiff inserts a plug-and-play motion module trained on large video datasets into personalized text-to-image models, enabling animation generation without altering the model's original weights or requiring specific tuning.
Core Problem
While personalized Text-to-Image (T2I) models (like DreamBooth/LoRA) generate high-quality static images, adding motion to create animations typically requires expensive model-specific fine-tuning or degrades the personalized visual quality.
Why it matters:
- Amateur users and artists want to animate their custom styles (e.g., cartoons, oil paintings) but lack the compute resources or video data for full training.
- Existing video generation methods often modify the original feature space, breaking compatibility with the vast library of community-created personalized T2I checkpoints.
- Directly training on video data can introduce quality degradation (motion blur, watermarks) compared to high-quality static image generators.
Concrete Example:
A user downloads a personalized 'ToonYou' model from Civitai to generate anime characters. If they try to use standard video generation techniques, they either lose the specific anime style or produce static, flickering images. AnimateDiff allows the 'ToonYou' model to generate smooth animations (e.g., a boy playing guitar) immediately without further training.
Key Novelty
Plug-and-Play Motion Module with MotionLoRA
- Trains a transferable 'motion module' (temporal transformers) on large video datasets once. This module can be inserted into *any* existing personalized Stable Diffusion model to animate it.
- Uses a 'Domain Adapter' during training to absorb the quality gap between low-quality video data and high-quality image models, preventing the motion module from learning artifacts.
- Introduces 'MotionLoRA', a lightweight adaptation technique that fine-tunes the motion module for specific camera movements (zoom, pan) using very few reference videos.
Architecture
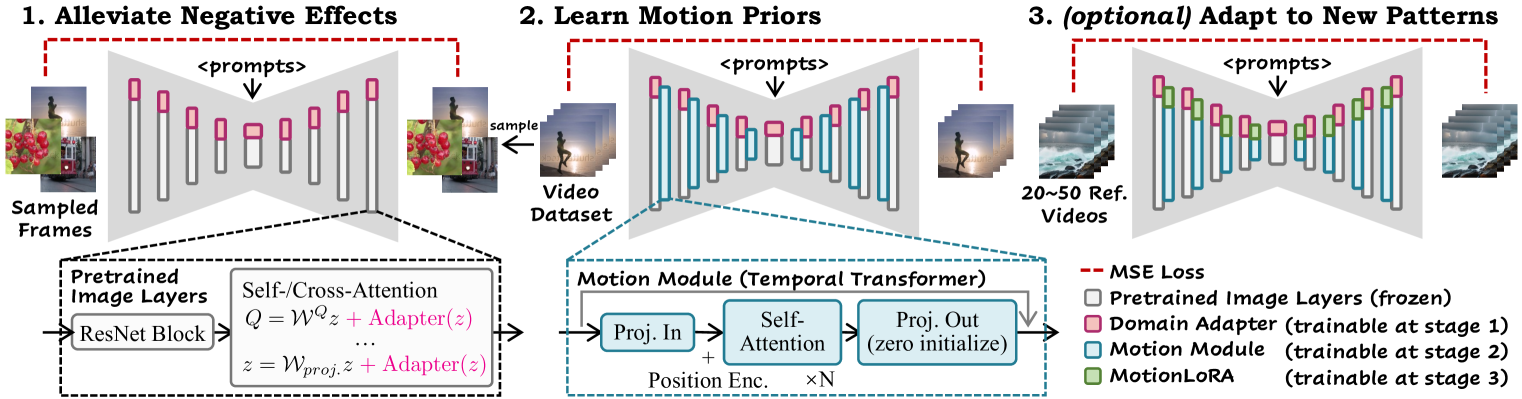
The training pipeline of AnimateDiff, showing the Base T2I, Domain Adapter, Motion Module, and MotionLoRA.
Evaluation Highlights
- MotionLoRA adapts to new motion patterns (e.g., zoom-in, rolling) using as few as 50 reference videos and ~30M storage space.
- Successfully animates diverse community models (Realistic Vision, ToonYou, Lyriel) while preserving their specific visual domains (cartoon, realistic, oil painting).
- Qualitative comparison shows AnimateDiff generates temporally smooth clips compatible with ControlNet, unlike baselines like Text2Video-Zero which rely on latent wrapping.
Breakthrough Assessment
8/10
Highly impactful for the generative AI community. It solved the compatibility issue between video generation and the massive ecosystem of personalized static image models, enabling widespread adoption of AI animation tools.