📝 Paper Summary
Federated Learning
Parameter-Efficient Fine-Tuning (PEFT)
Personalization
Benchmarks federated prompt tuning for LLMs, demonstrating that adaptive client optimizers and regularization techniques are essential for balancing local personalization accuracy with global model robustness.
Core Problem
In federated learning, adapting a global model to local client data (personalization) often causes the model to forget general knowledge (loss of robustness), a trade-off largely unexplored in the context of prompt tuning for Large Language Models (LLMs).
Why it matters:
- Federated systems are moving toward fine-tuning foundation models, where communication constraints necessitate Parameter-Efficient Fine-Tuning (PEFT) methods like prompt tuning.
- Clients require models that work well on their specific data without losing the broad capabilities of the pre-trained global model.
- Understanding how hyperparameters affect catastrophic forgetting in federated PEFT is critical for designing effective deployed systems.
Concrete Example:
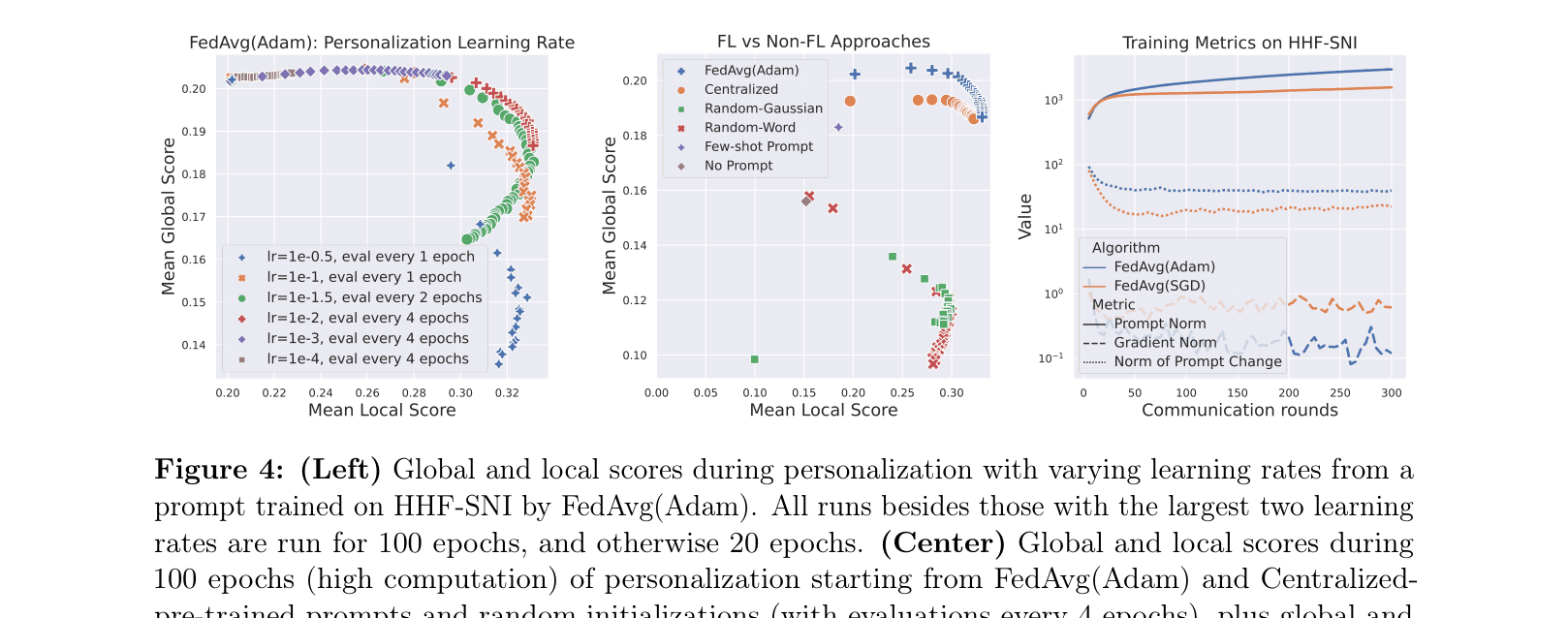
A client fine-tunes a global prompt on their local translation tasks. Using a high learning rate (10^-0.5), the model achieves a high local score (0.32) quickly but 'forgets' global knowledge, causing the global score to drop to 0.15. Conversely, a lower learning rate preserves global knowledge (score > 0.19) but requires 6x more training epochs to personalize.
Key Novelty
Benchmarking Personalization-Robustness in Federated Prompt Tuning
- Systematically evaluates the trade-off between local adaptation (personalization) and global knowledge retention (robustness) using PaLM-8B soft prompts across varying data heterogeneity levels.
- Identifies that using an adaptive optimizer (Adam) specifically on the *client* side during federated averaging is critical for effective prompt tuning, unlike in full-model federated learning.
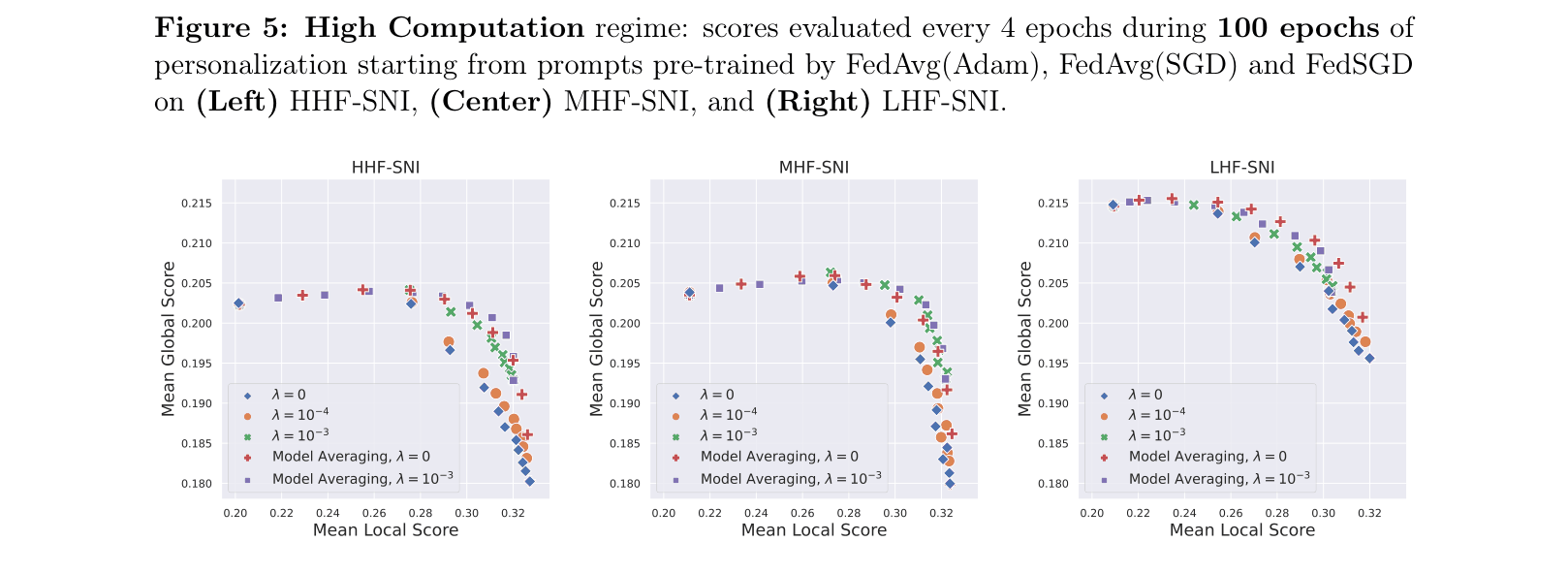
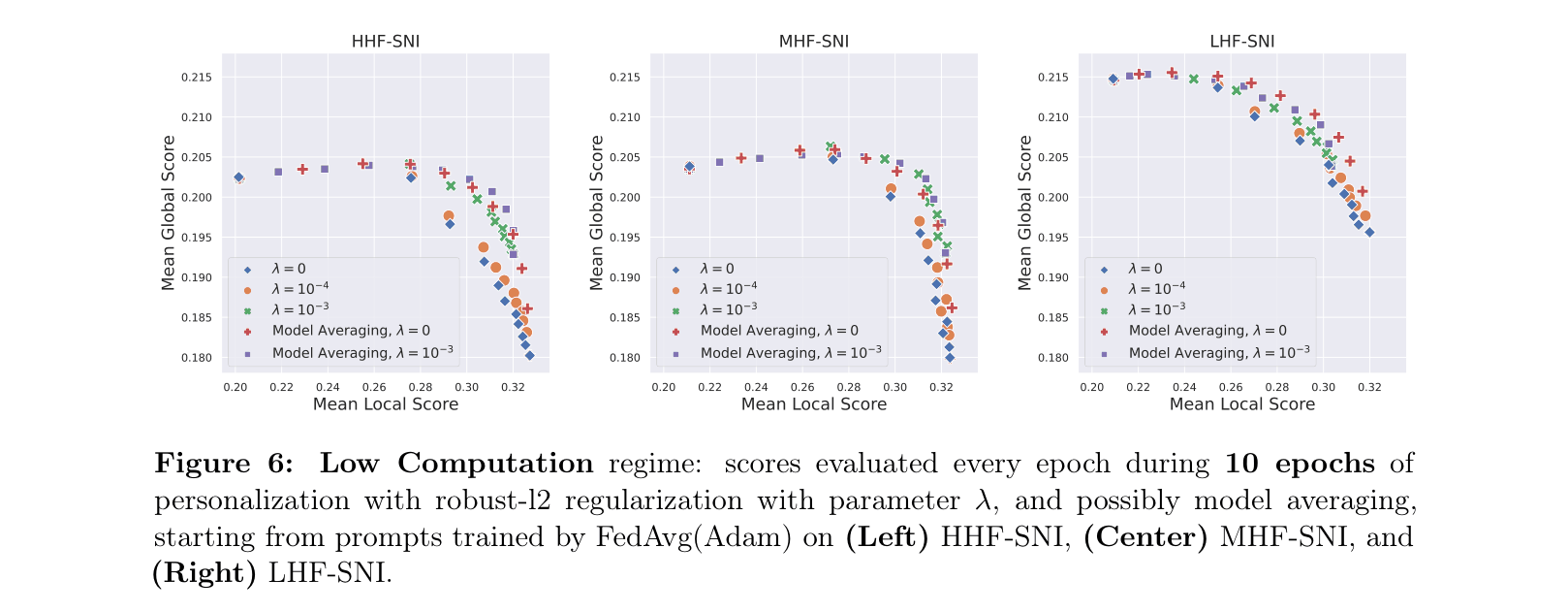
- Demonstrates that simple heuristics like model averaging (interpolating local and global prompts) and L2 regularization can mitigate catastrophic forgetting in computation-limited settings.
Architecture
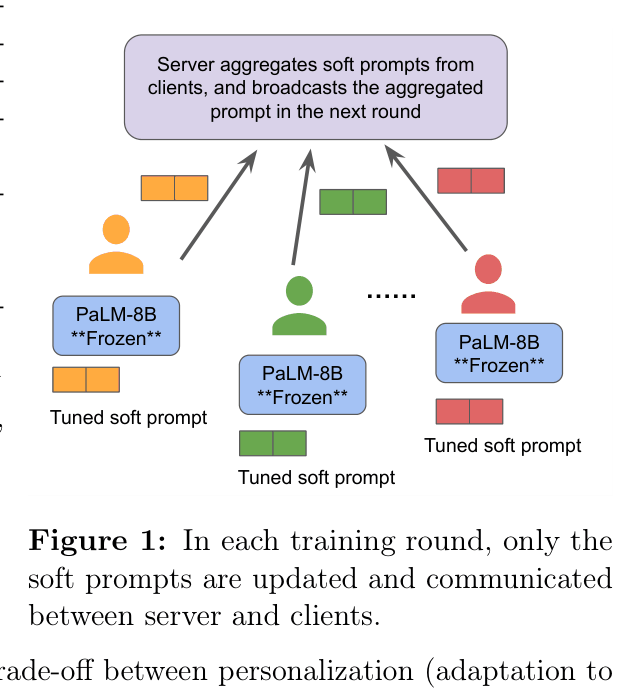
The federated prompt tuning workflow. The Server aggregates soft prompts from clients. Clients keep the PaLM-8B model frozen and only tune/communicate the soft prompt.
Evaluation Highlights
- FedAvg(Adam) achieves superior personalization/robustness trade-offs compared to FedAvg(SGD) and Centralized training, with FedAvg(SGD) gradients being 3 orders of magnitude smaller.
- Lower personalization learning rates (10^-2) maintain higher global robustness (score > 0.19) compared to higher rates (score drops to 0.15), at the cost of requiring more epochs (64 vs 10).
- Model averaging and L2 regularization successfully improve the trade-off curve in low-computation regimes (10 local epochs), reducing the drop in global score during personalization.
Breakthrough Assessment
6/10
While not proposing a new architecture, this is a foundational benchmark for a specific, increasingly important niche (Federated PEFT). It provides counter-intuitive insights (FL outperforming centralized; importance of client-side Adam) that guide future system design.