📝 Paper Summary
Personalized Federated Learning (PFL)
Decentralized Federated Learning (DFL)
DFedAlt and DFedSalt achieve superior personalized federated learning by decoupling models into local-only and shared parts, updating them alternately, and stabilizing the shared component via sharpness-aware minimization.
Core Problem
Centralized Personalized Federated Learning suffers from single-point failure risks and communication bottlenecks, while existing decentralized methods share full models, causing 'catastrophic forgetting' of unique local features.
Why it matters:
- Centralized servers are vulnerable to disruption and bandwidth constraints in real-world FL systems
- Full model aggregation in decentralized settings dilutes the specific knowledge required for highly heterogeneous client data
- Optimizing personalized performance in peer-to-peer networks is difficult due to the lack of a global coordinate to align model parameters
Concrete Example:
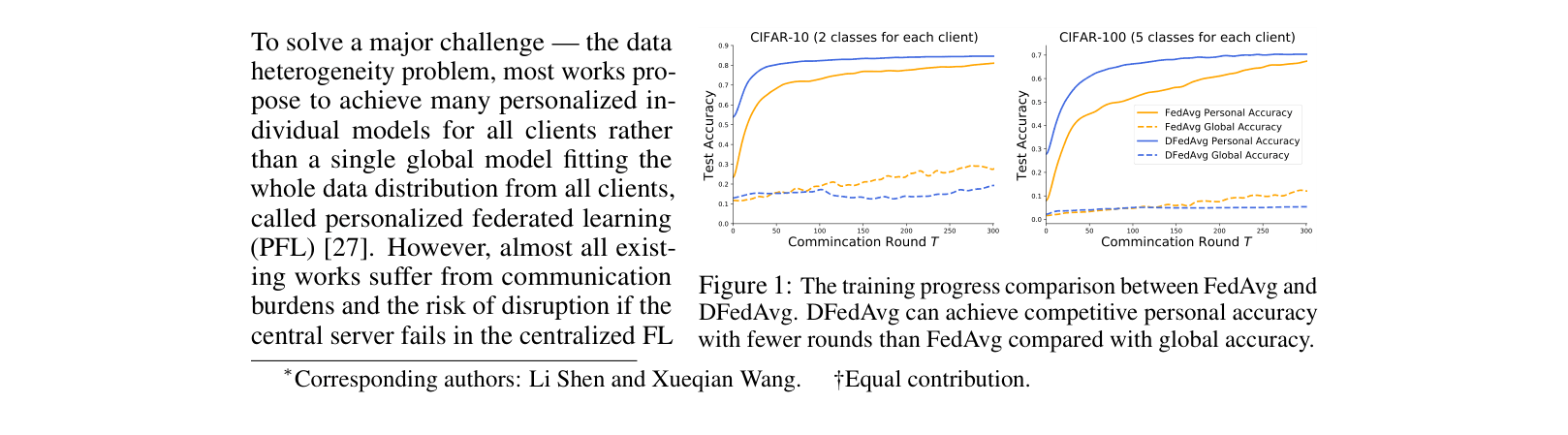
In a decentralized network where one client classifies only 2 distinct CIFAR-10 classes, standard Decentralized FedAvg forces it to average its full model with neighbors holding different classes. This dilutes its specialized weights, resulting in lower accuracy (e.g., ~54% vs 66% for partial personalization) because the unique local information is overwritten by irrelevant neighbor features.
Key Novelty
Decentralized Partial Model Training (DFedAlt) & Sharpness-Aware Decentralized Training (DFedSalt)
- Decomposes the model into a 'personal' head (kept local) and a 'shared' body (gossiped with neighbors), updating them alternately to preserve local specificity while leveraging shared feature extraction
- Integrates Sharpness-Aware Minimization (SAM) into the shared parameters' update (DFedSalt), adding perturbations to find flat minima that generalize better across heterogeneous clients
Architecture
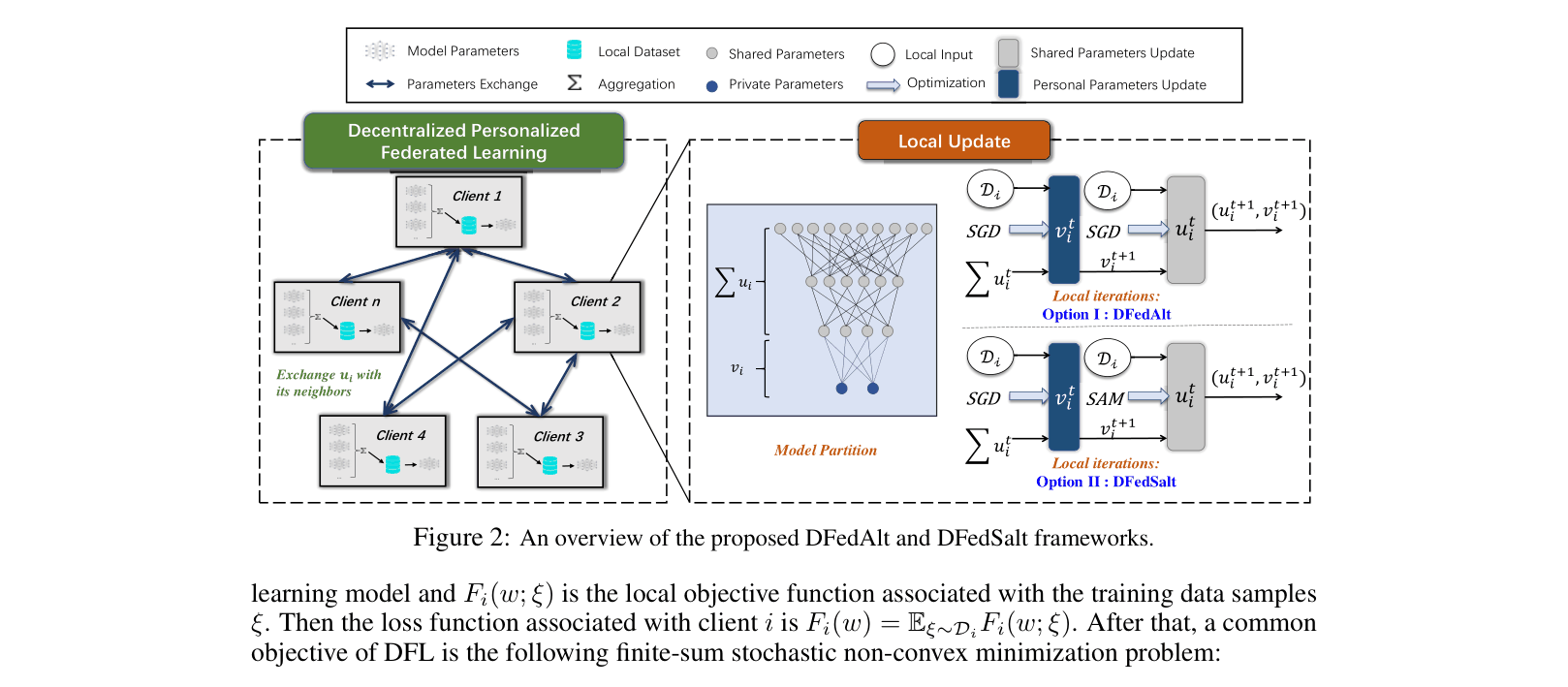
Overview of DFedAlt and DFedSalt frameworks showing the alternating update and communication flow.
Evaluation Highlights
- +1.99% accuracy improvement on CIFAR-10 (Dirichlet-0.3) compared to the best centralized baseline (Fed-RoD)
- +7.16% accuracy improvement on CIFAR-100 (Pathological-10) compared to the best decentralized baseline (DFedSAM)
- Achieves target accuracy in ~160 rounds vs. ~354 rounds for standard decentralized methods (DFedAvgM) on CIFAR-10, demonstrating significantly faster convergence
Breakthrough Assessment
8/10
Successfully marries decentralized learning with partial personalization, outperforming both centralized SOTA and full-model decentralized methods. The theoretical analysis in a non-convex setting is a strong addition.