📝 Paper Summary
Federated Learning (FL)
Resource-constrained Edge AI
Personalization
A wireless Federated Learning framework that reduces latency by pruning the shared global model while maintaining local personalized parameters to handle data heterogeneity.
Core Problem
Standard Federated Learning suffers from high communication/computation latency on resource-constrained devices and poor accuracy on non-IID data due to heterogeneity.
Why it matters:
- Edge devices often have limited bandwidth and battery, making the transmission of large full models prohibitive.
- Data heterogeneity (non-IID data) causes global models to drift, resulting in poor generalization and low accuracy for individual users.
- Existing pruning methods often fail to account for the dynamic wireless channel conditions and data heterogeneity simultaneously.
Concrete Example:
A mobile device with poor channel conditions trying to upload a full CNN model for image classification experiences high latency, slowing down the entire synchronized FL round. Additionally, a global model trained on diverse data may fail to recognize specific local patterns (e.g., specific handwriting styles in MNIST).
Key Novelty
Joint Adaptive Pruning and Personalization (JAPP-FL)
- Splits the model into a personalized part (kept local) and a global part (shared but pruned), allowing devices to retain specific features while learning general representations.
- Uses KKT conditions to mathematically derive closed-form solutions for the optimal pruning ratio and bandwidth allocation, balancing latency constraints against learning accuracy.
Architecture
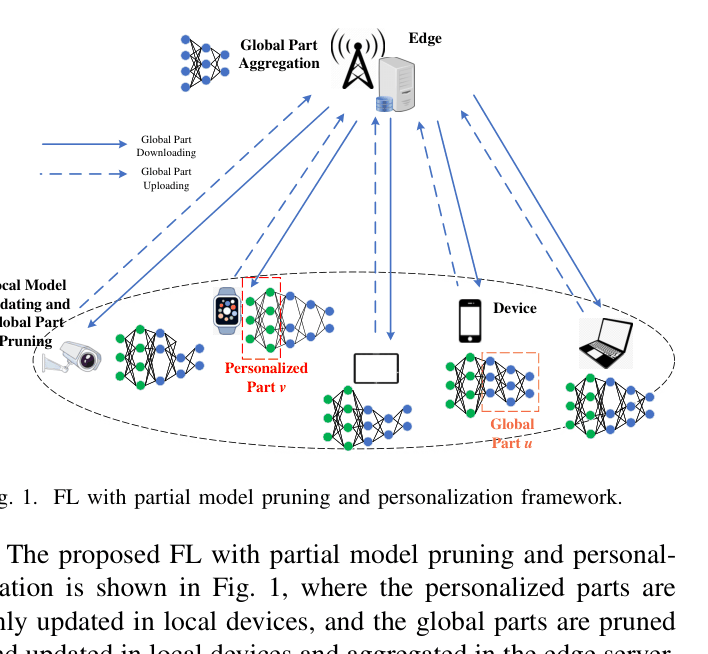
The FL framework showing the split between Personalized Part (kept local) and Global Part (pruned and shared).
Evaluation Highlights
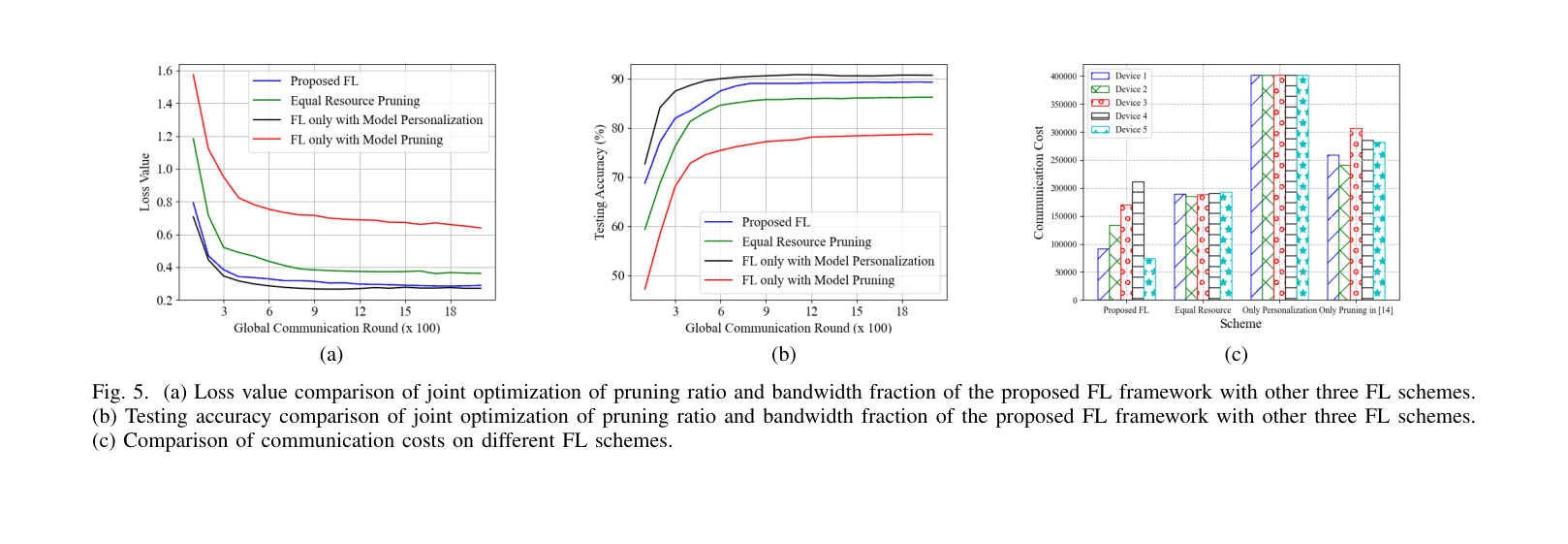
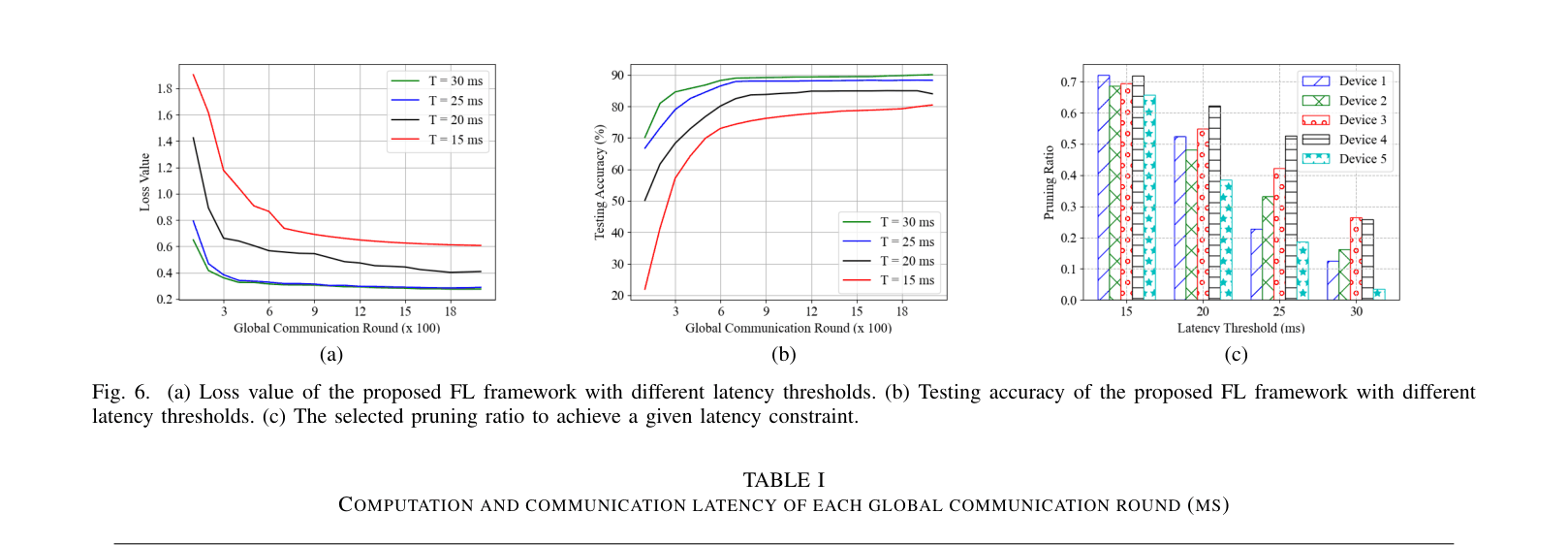
- Reduces computation and communication latency by approximately 50% compared to FL with only partial model personalization.
- Maintains comparable testing accuracy to unpruned personalized FL baselines on non-IID Fashion MNIST.
- Achieves faster convergence in terms of global rounds compared to equal resource pruning schemes.
Breakthrough Assessment
7/10
Strong theoretical contribution with closed-form resource allocation and significant latency reduction. However, validation is limited to basic datasets (MNIST/Fashion MNIST) and standard CNNs.