📝 Paper Summary
Personalized Federated Learning (pFL)
Parameter-Efficient Fine-Tuning (PEFT)
PerAda combines parameter-efficient adapters with server-side knowledge distillation to achieve personalized federated learning that is computationally cheap and generalizes well to distribution shifts.
Core Problem
Existing personalized FL methods either incur high communication/computation costs (full model personalization) or overfit to local data, failing to generalize to test-time distribution shifts (partial personalization).
Why it matters:
- Clients often have limited bandwidth and compute resources, making full model transmission impractical.
- Real-world data is non-IID and evolves over time (e.g., lighting changes in medical imaging), causing standard partial personalization to fail on out-of-distribution test samples.
- Partial personalization methods (updating only specific layers) often fail to encode generalized knowledge needed for robust performance.
Concrete Example:
In medical imaging, a hospital might train a model on X-rays from specific machines. A standard personalized model might overfit to these machines' specific artifacts. When testing on images with slight natural shifts (e.g., different lighting), the model fails because it lacks generalized features from the global distribution.
Key Novelty
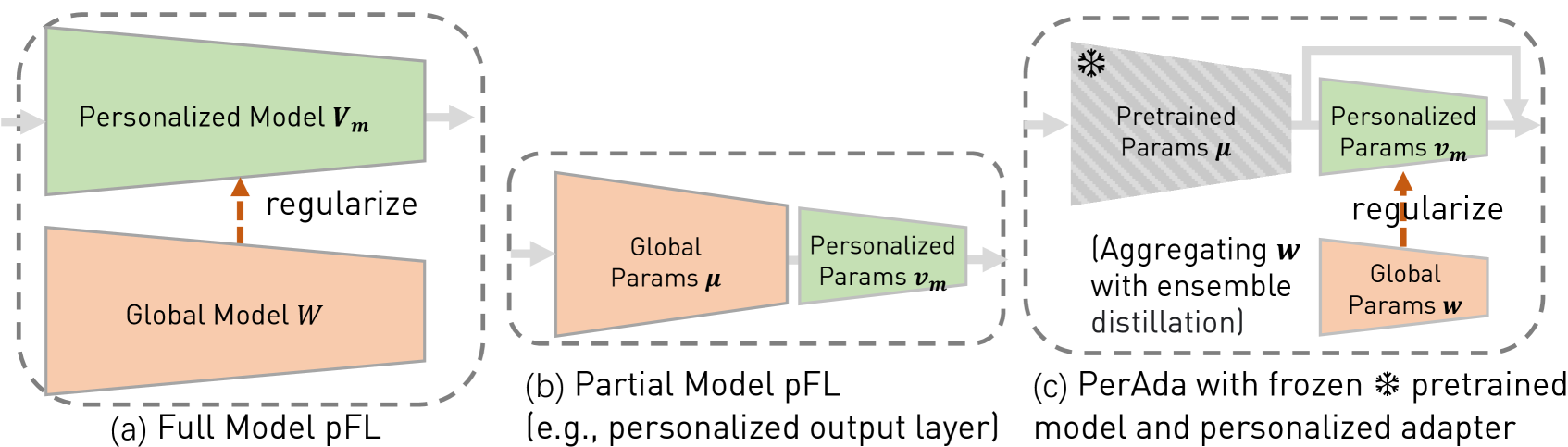
PerAda (Personalized Adapters with Knowledge Distillation)
- Inserts small, trainable adapter modules into a frozen pre-trained model for each client to reduce communication costs.
- Uses server-side ensemble distillation on an unlabeled public dataset to aggregate knowledge into a 'global adapter', avoiding direct parameter averaging of heterogeneous models.
- Regularizes each client's local personalized adapter towards this distilled global adapter to prevent overfitting while retaining personalization.
Architecture
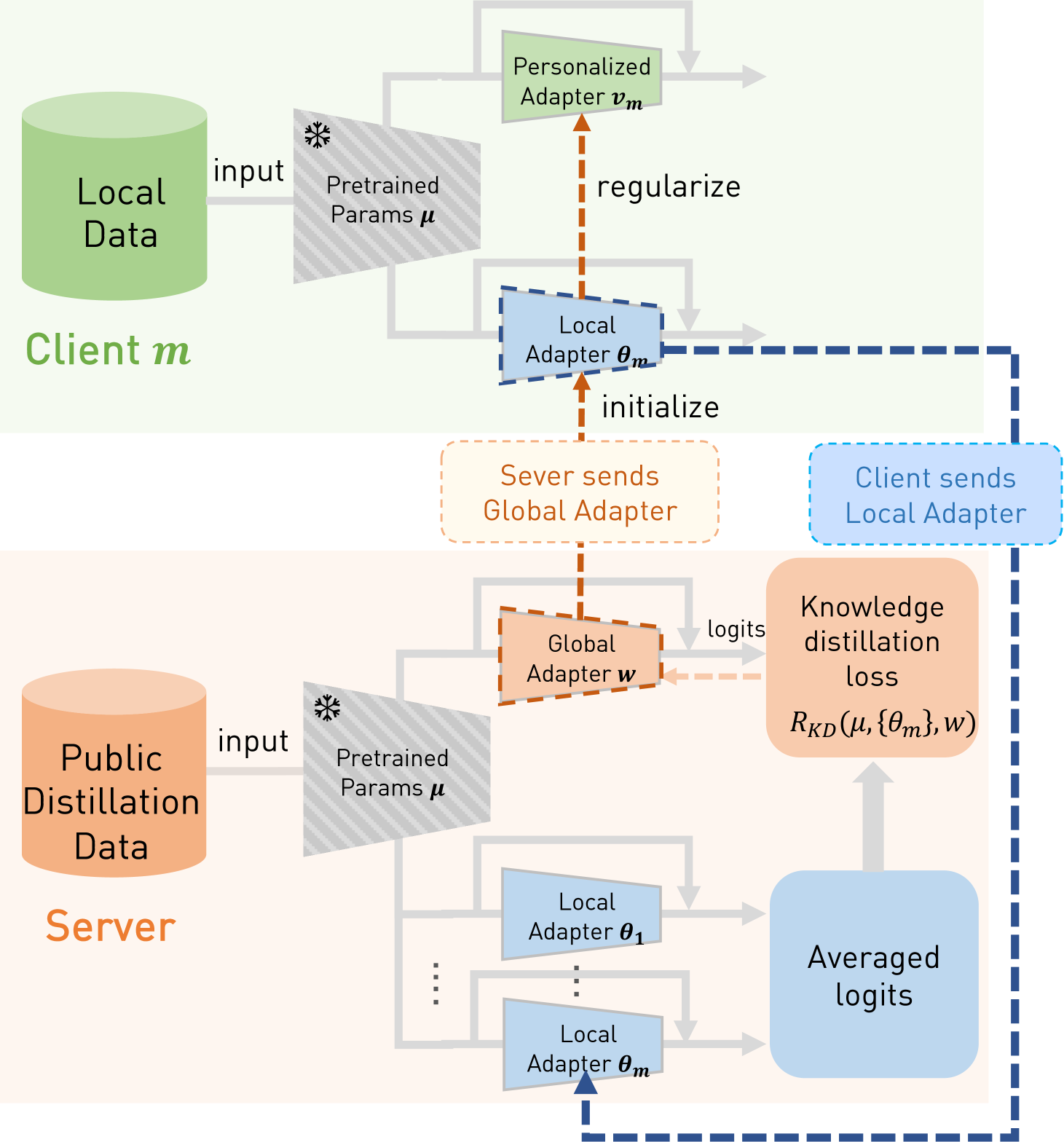
Overview of PerAda framework showing the interaction between client and server.
Evaluation Highlights
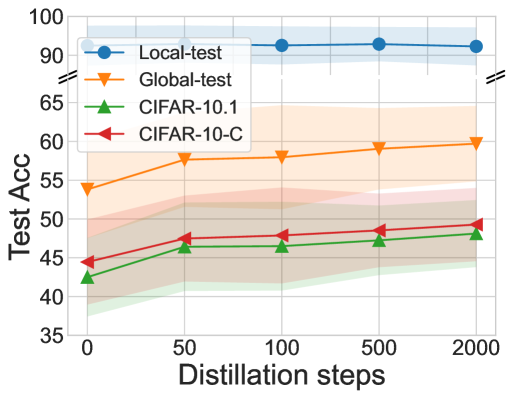
- +4.85% personalized accuracy on CheXpert (medical imaging) compared to partial personalization baselines.
- +5.23% accuracy on CIFAR-10-C (out-of-distribution robustness) compared to baselines.
- Updates only 12.6% of parameters per model, significantly reducing communication and computation overhead compared to full fine-tuning.
Breakthrough Assessment
8/10
Strong theoretical grounding (first convergence proof for FL with server distillation) combined with significant empirical gains in efficiency and OOD generalization makes this a valuable contribution to practical FL.