📝 Paper Summary
Personalized Federated Learning (PFL)
Vision Transformers (ViTs)
FedPerfix personalizes Vision Transformers in federated learning by keeping only the most sensitive layers (self-attention and classification head) local and enhancing them with stable, learnable prefix plugins.
Core Problem
Existing partial personalization methods are designed for CNNs and don't account for the specific architecture of Vision Transformers (ViTs), where different layers exhibit varying sensitivity to data heterogeneity.
Why it matters:
- One-model-fits-all FL fails on non-IID data, necessitating personalization to handle client heterogeneity.
- Full model personalization is resource-intensive; partial personalization is efficient but requires knowing exactly where and how to personalize.
- ViTs outperform CNNs in many tasks, but their application and personalization in federated learning remain under-explored compared to CNNs.
Concrete Example:
When aggregating a ViT model across clients with label skew (e.g., different class distributions), the self-attention mechanism's weights may become averaged and generic, losing the ability to attend to client-specific features efficiently.
Key Novelty
Federated Personalized Prefix-tuning (FedPerfix)
- Empirically identifies that self-attention layers and classification heads in ViTs are the most sensitive to data distribution, making them ideal targets for personalization.
- Uses 'Prefix' plugins (learnable vectors appended to attention keys/values) as personalization modules to adapt the global model to local data without modifying shared weights.
- Stabilizes prefix training using a local adapter mechanism (parallel attention) to prevent instability caused by random initialization.
Architecture
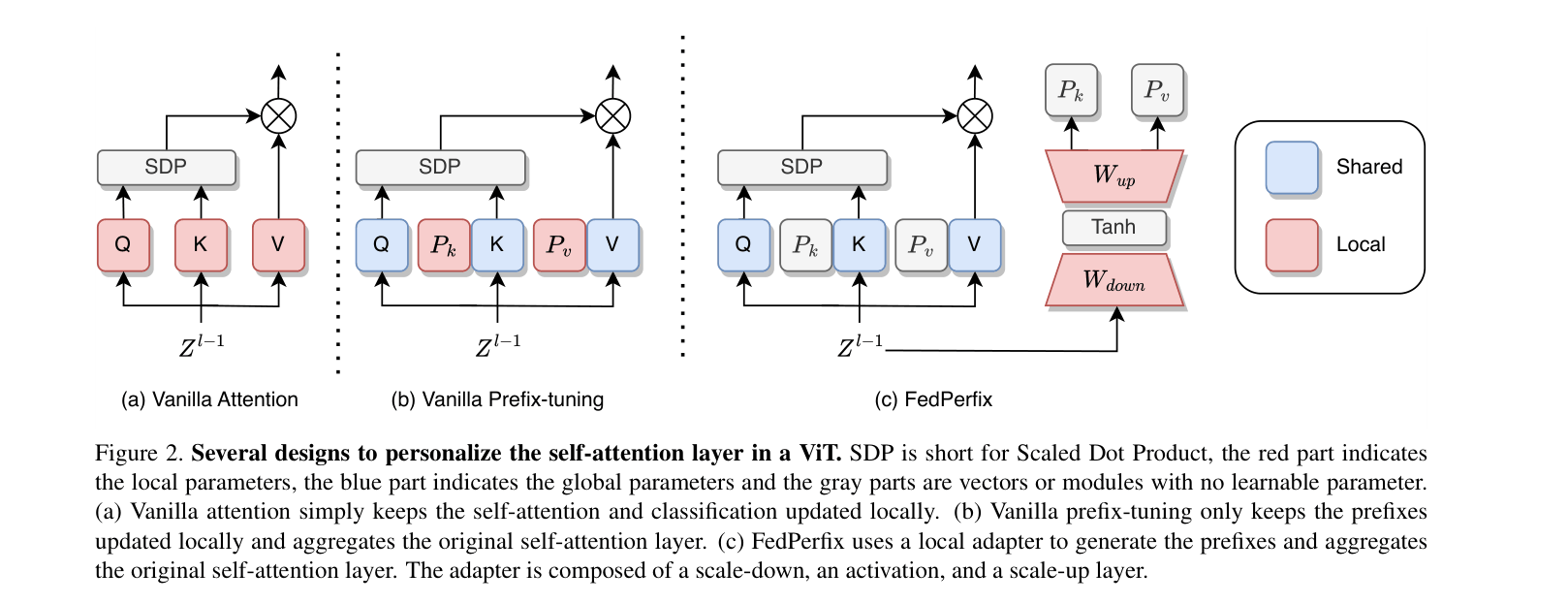
Comparison of Vanilla Attention, Vanilla Prefix-tuning, and the proposed FedPerfix architecture for self-attention layers.
Evaluation Highlights
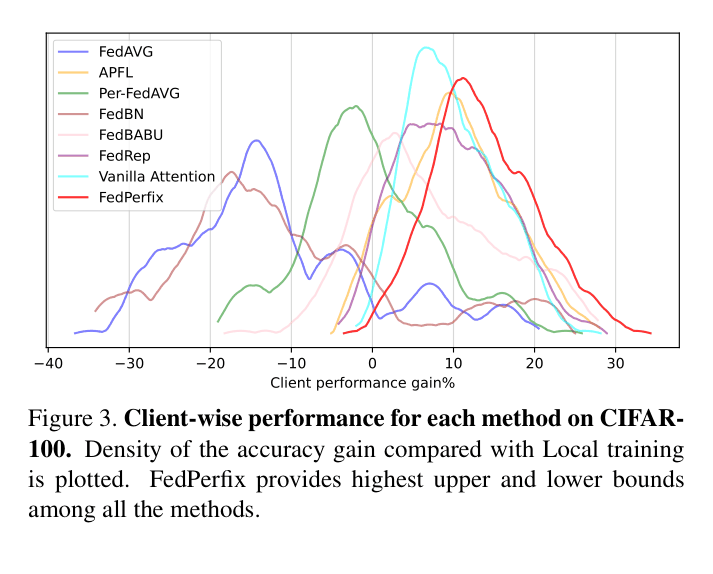
- Outperforms state-of-the-art methods by +3.22% accuracy on CIFAR-100 (non-IID) compared to the next best method (APFL).
- Achieves superior performance while reducing communication costs by ~2% compared to full model aggregation baselines like FedAvg.
- Demonstrates robustness across varying levels of data heterogeneity and client participation rates, maintaining a +3-4% lead over baselines.
Breakthrough Assessment
7/10
Provides a solid empirical analysis of ViT layer sensitivity in FL and successfully adapts parameter-efficient transfer learning techniques (Prefixes) to PFL, outperforming CNN-centric baselines.