📝 Paper Summary
Linear memory (buffer management)
Conversational personalization
A framework for on-device LLM personalization selects representative data via unsupervised metrics and synthesizes semantic variations to enable efficient fine-tuning with limited storage and sparse annotation.
Core Problem
On-device personalization faces conflicting constraints: limited storage prevents keeping all user data, privacy prevents cloud offloading, and user annotations must remain sparse to avoid annoyance.
Why it matters:
- Generic pre-trained models fail to adapt to individual user contexts, preferences, and unique interaction habits in real-time
- Standard fine-tuning assumes large storage and IID (Independent and Identically Distributed) data sampling, which is impossible with streaming edge data
- Existing continual learning methods struggle with temporally correlated streams where data value varies significantly over time
Concrete Example:
A user interacts with a robot assistant. The stream contains repetitive, low-value 'uncontroversial dialogue' before switching to a useful, unique interaction. Standard buffers might fill up with the repetitive data due to temporal correlation, discarding the unique interaction and preventing personalization.
Key Novelty
Self-Supervised Data Selection and Synthesis (SDSS)
- Selects data for a small memory buffer using three unsupervised metrics: entropy (information content), domain score (relevance), and dissimilarity (uniqueness vs. buffer)
- Augments the small selected dataset by prompting the LLM to synthesize multiple semantically similar question-answer pairs, acting as a data multiplier without user effort
Architecture
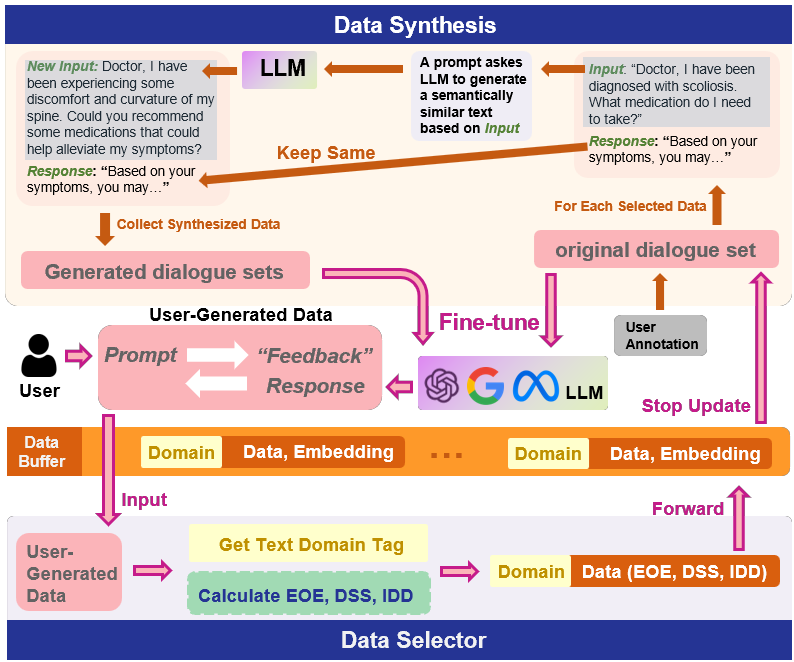
The three-stage framework: (1) Data Selection using quality metrics, (2) Data Synthesis using the LLM, and (3) Fine-tuning.
Evaluation Highlights
- Achieves up to 38% higher ROUGE-1 score compared to vanilla baselines on datasets like ALPACA and MedDialog
- Demonstrates improved learning speed and content-generating accuracy by fine-tuning only on high-value, representative data rather than random samples
Breakthrough Assessment
7/10
First framework specifically targeting on-device LLM personalization with a complete pipeline for selection and synthesis, though primarily an engineering integration of known concepts.