📝 Paper Summary
User-profile based personalization
Modularized RAG pipeline
Augmenting retrieval-based personalization with offline LLM-generated user summaries improves performance and reduces context length usage, especially in sparse data scenarios.
Core Problem
Personalizing LLMs via full user history hits input length limits and latency costs, while standard retrieval suffers from information loss and cold-start issues.
Why it matters:
- Full history prompts exceed context windows and degrade model performance due to length
- Retrieval-only methods miss high-level abstractions of user style and struggle with new users (cold-start)
- Real-time voice assistants require low latency, making heavy online processing impractical
Concrete Example:
A baseline retrieval model incorrectly guesses a citation preference because it retrieves irrelevant papers. The proposed model uses a summary of the user's research interests ('network architecture', 'wireless security') to correctly identify the relevant citation.
Key Novelty
Summary-Augmented Retrieval for Personalization
- Generate task-aware summaries of user history offline using an instruction-tuned LLM (Vicuna or ChatGPT) to capture high-level preferences
- At runtime, concatenate this pre-computed summary with a smaller set of retrieved items to form the prompt
- Combines the specific detail of retrieval with the broad context of summarization without increasing inference latency
Architecture
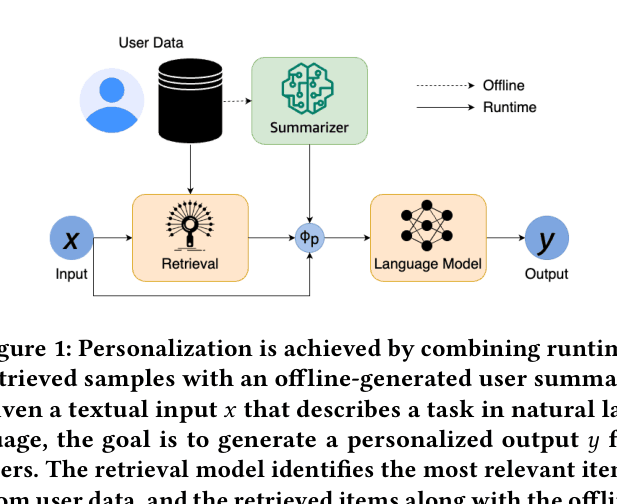
The workflow combining offline summarization and runtime retrieval for personalization.
Evaluation Highlights
- Summary-augmented method with 75% less retrieved data (k=1 vs k=4) matches or outperforms baselines on 5 out of 6 LaMP tasks
- GPT-3.5 summaries with zero retrieval (k=0) outperformed the retrieval baseline (k=4) on the Citation Identification task (+2.9% accuracy)
- Summarization consistently helps cold-start/sparse scenarios where retrieval fails to find sufficient context
Breakthrough Assessment
7/10
Practical and effective hybrid approach tackling real-world constraints (latency/context window). While methodologically straightforward, the strong performance with reduced retrieval is significant for production systems.