📝 Paper Summary
Modularized RAG pipeline
By applying the 'nugget' evaluation methodology—decomposing answers into atomic facts—to Search Arena battles, this work shows that automated nugget scores correlate strongly with human preferences and offer diagnostic insights.
Core Problem
Existing side-by-side 'battle' evaluations (like Chatbot Arena) for RAG systems rely on human preference without being explanatory or diagnostic; they tell you which model won but not why or how to fix it.
Why it matters:
- Developers need actionable guidance to improve RAG systems beyond just a win/loss ratio.
- Understanding 'why' a user preferred one response over another is crucial for transparency and debugging complex information-seeking queries.
Key Novelty
Automated Nugget-Based Evaluation for Search Arena Battles
- Adapts the AutoNuggetizer framework to the Search Arena dataset (approx. 7K battles).
- Extracts atomic facts (nuggets) from queries, retrieved docs, and model responses using GPT-4.
- Scores models based on how many 'vital' or 'okay' nuggets they cover.
- Compares these automated scores directly against human preference labels.
Architecture
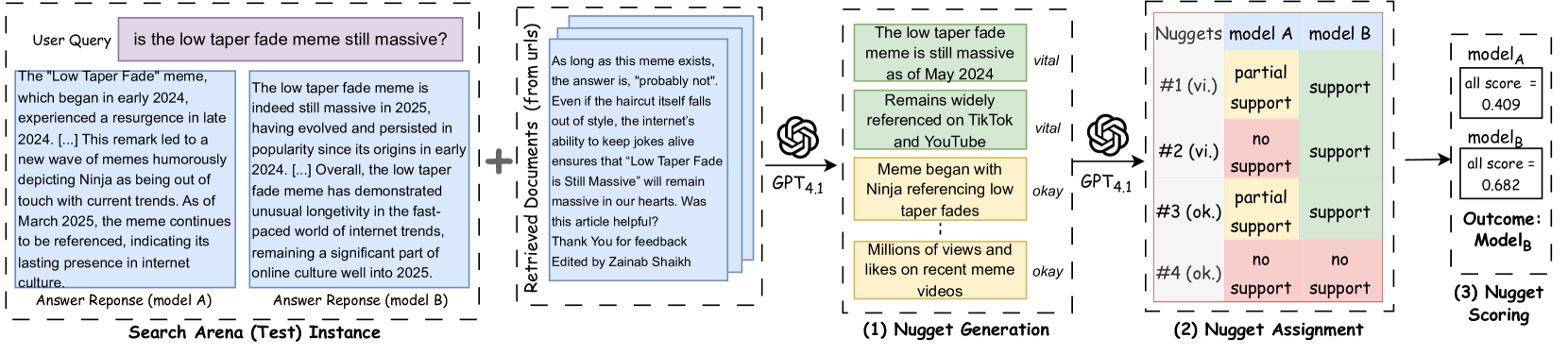
The end-to-end AutoNuggetizer pipeline: Query -> Nugget Generation (Vital/Okay) -> Nugget Assignment (Support/No Support) -> Scoring -> Outcome.
Evaluation Highlights
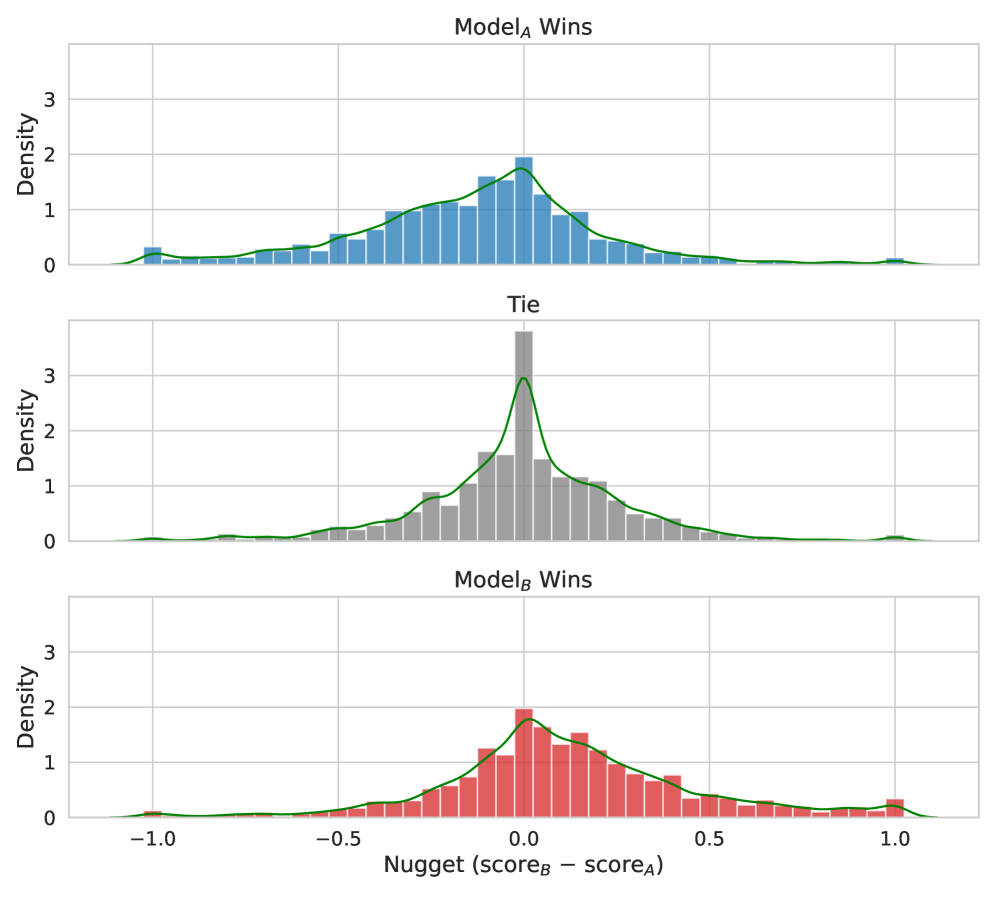
- Distributions of nugget score differences are statistically distinct for 'Model A Wins', 'Model B Wins', and 'Tie' (K-S test p-values < 1.2e-24).
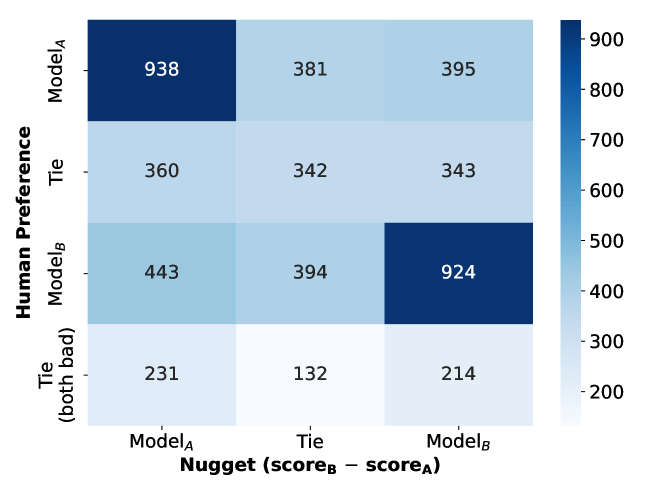
- Nugget preference aligns with human preference in ~54.7% of cases where Model A wins and ~52.5% where Model B wins.
- Nugget-based evaluation had lower preference inversion rates compared to a standard LLM-as-a-judge baseline (817 inversions vs 1102).
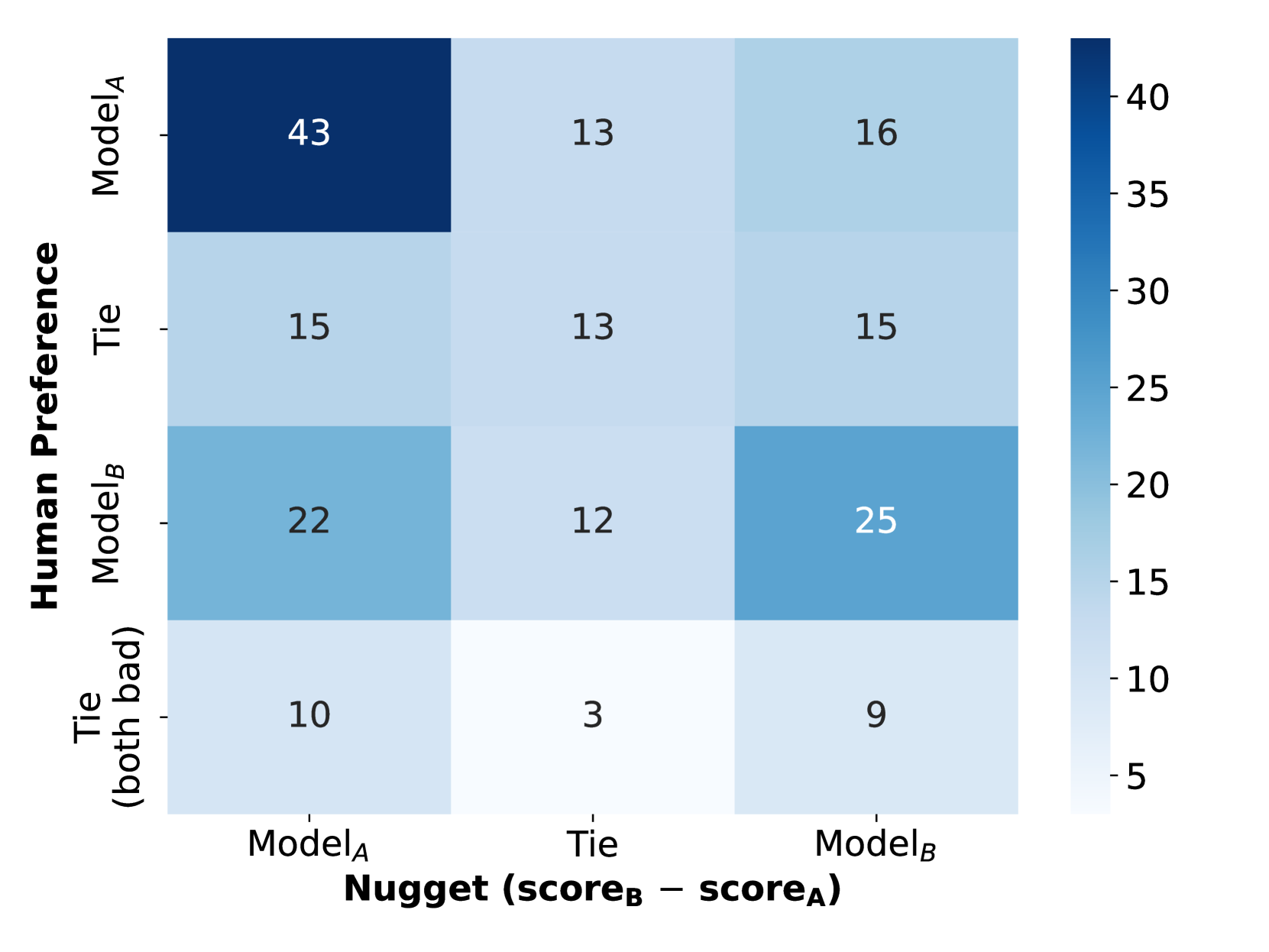
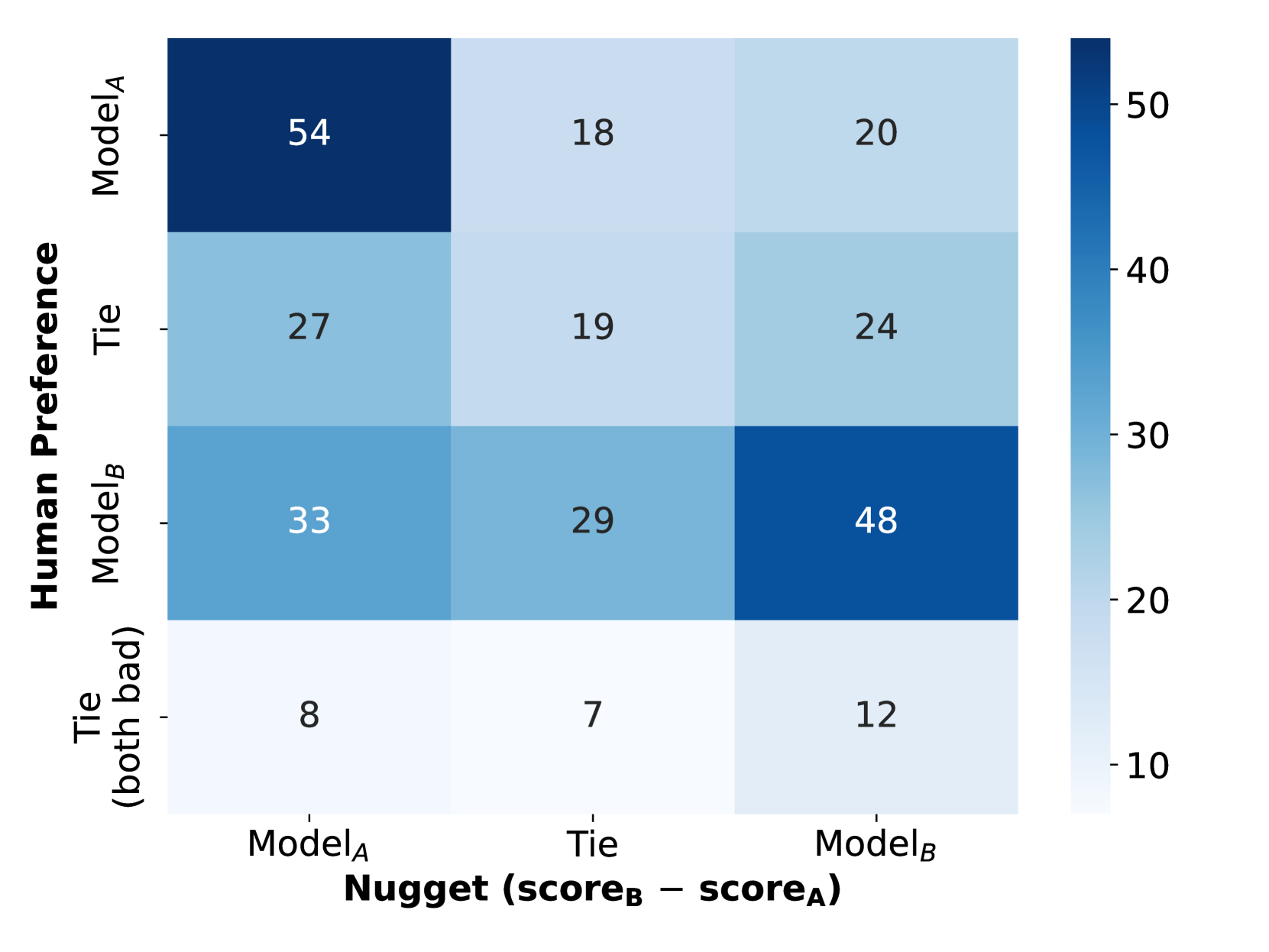
- Disagreement (inversion) is highest for German queries (20%) and ambiguous/assumptive queries (19%/18%).
- Using only LLM responses (without URL content) for nugget generation performs comparably to using full URL content (54.8% vs 54.7% agreement for Model A wins).
Breakthrough Assessment
7/10
It provides a strong validation of the nugget methodology on a popular, real-world RAG benchmark (Search Arena). While the core methodology (AutoNuggetizer) existed, applying it here offers a concrete path toward interpretable RAG evaluation, addressing a major gap in current 'Arena' style leaderboards.